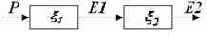В Table 16 показан процесс последовательного кодирования и декодирования с помощью двух последовательно включенных КАМСИ-автоматов А1 и А2.
Рассмотрим теперь способ построения композиции последовательно включенных двух КАМСИ-автоматов.
Алгоритм построения КАМСИ–композиции из компонентов КАМСИ рассмотрим на примере композиции двух автоматов.
Пример 2
Пусть заданы две КАМСИ ?1 и ?2
(см. Table 18 (а) и (b)). Построим таблицу переходов автомата ?, эквивалентного последовательному соединению КАМСИ ?1>?2.
P,E1
P=0
P=1
A
B,0
A,0
B
A,1
B,1
(a)
Е1,E2
P=0
P=1
A
A,1
B,1
B
B,0
A,0
(b)
?
P,E2
P=0
P=1
1
2
3
AA
BA,1
AA,1
AB
BB,0
AB,0
BA
AB,1
BB,1
BB
AA,0
BA,0
(c)
?
P,E2
P=0
P=1
A
C,1
A,1
B
D,0
B,0
C
B,1
D,1
D
A,0
C,0
(d)
Table 18
P
1
1
0
1
0
0
1
1
0
0
1
0
0
1
1
1
(a)
?
A
A
A
C
D
A
C
D
C
B
D
C
B
D
C
D
C
(b)
1
1
1
1
0
1
1
0
1
0
0
1
0
0
1
0
(c)
SS2
S0
S2
S4
S4
S4
S3
S2
S4
S3
S2
S3
S1
S2
S3
S1
S2
S3
(d)
E
0
1
0
0
0
1
1
0
1
1
1
0
1
1
0
1
(e)
SS1
S0
S1
S2
S3
S1
S1
S2
S4
S3
S2
S4
S4
S3
S2
S4
S3
S2
(f)
1
1
0
0
1
1
0
1
0
0
1
1
0
0
1
0
(g)
Table 19
Для построения композиции выполним последовательность операций:
создать таблицу переходов, содержащую 2х2=4 ([14]) строки;
в первом столбце вписать все сочетания по два состояний КАМСИ ?1
и ?2 при этом необходимо, чтобы первым стояло обозначение состояния ?1, а вторым – ?2;
на пересечении АА (см. первую строку Table 18(с)) и столбца Р=0 записать:
символ В (переход при Р=0 в КАМСИ ?1 из А в В, Е1=0);
символ А (переход при Е1=0 в КАМСИ ?2 из А в А, Е2=1);
через запятую записать значение Е2 равное 1; Аналогично заполнить остальные клетки столбцов 2 и 3.
построить Table 18(d). Для этого АА из Table 18 (с) заменить: АА на А, АВ на В, ВА на С и ВВ на D ([15]).
Приведенный пример показывает, что если число компонентов КАМСИ в композиции равно m, и таблица переходов i-го автомата имеет ni состояний, то общее число N состояний композиции равно
.
Примеры на стр. 26 и 29 позволяют сформулировать следующее утверждение:
Утверждение 6: «Последовательному соединению m компонентов КАМСИ соответствует КАМСИ-композиция, которая имеет µ-порядок, равный
и таблицу переходов с
состояниями».
Доказательство этого Утверждения можно провести по индукции, если считать, что примеры на стр. 26 и 29 позволяют доказать это утверждение для m=2.
Далее, можно продолжить доказательство, увеличивая m на единицу.
Сформулируем еще одно Утверждение:
Утверждение 7. Для md КАМСИ-автоматов декомпозиции ([16]) КАМСИ, всегда выполняется условие ?d ? ?, где: µd
- µ-порядок последовательного соединения КАМСИ-компонентов, равный:
, а µ - µ-порядок исходной КАМСИ-композиции.
Допустим обратное, то есть условие Утверждения не выполняется, то есть ?d > ?. Если это так, то, в соответствии с «Утверждение 6» композиция этих mdk
КАМСИ-компонентов должна иметь µ-порядок, больший, чем исходная КАМСИ. Это значит, что в результате композиции компонентов мы получим ту же КАМСИ, но с бОльшим µ-порядком, что не возможно.
Из приведенных Утверждений можно сделать следующие выводы.
Следствие 1. Если композиция КАМСИ состоит из минимизированных компонентов КАМСИ, то ее таблица переходов не имеет эквивалентных состояний.
Введем определение:
Определение. 9 КАМСИ, которая является компонентом композиции, называется КАМСИ-примитивом ([17]).
Примером КАМСИ-примитива являются КАМСИ ?1 или ?2, приведенные в Table 18(a), (b) , а КАМСИ-композиция показанная в Table 18(d) - ?.
Дополнение
В этом разделе мы приводим некоторые примеры, которые могут дополнить информацию о КАМСИ.
Физический аналог
Число
Время до следующего оледенения
14000 (214)
Время до превращения Солнца в сверхновую звезду
109 (230)
Возраст планеты
109 (230)
Возраст Вселенной
1010 (234)
Число атомов планеты
1051 (2170)
Число атомов Солнца
1057 (2190)
Число атомов галактики
1067 (2223)
Число атомов Вселенной
1077 (2280)
Объем Вселенной
1084 (2280) sm3
Table 23 Большие числа
P,E
P=0
P=1
A
A,0
C,1
B
C,0
D,0
C
B,0
D,1
D
A,1
B,1
P,E
E=0
E=1
A
A
C
B
CD
C
B
D
D
AB
AB
(AC)(AD)
CD
(AD)(BD)
AC
AB
CD
AD
(AC)(BC)
BD
Table 24. Процесс определения ?-порядка КАМСИ.
a1
P,E
P=0
P=1
A
A,0
E,0
B
D,0
F,0
C
F,1
C,1
D
B,1
E,1
E
C,0
B,0
F
A,1
D,1
a1
P,E
P=0
P=1
A
AE
B
DF
C
CF
D
BE
E
BC
F
AD
AE
(AB)(AC)
(DE)(EF)
DF
(AB)(BD)
(AE)(DE)
CF
(AC)(CD)
(AF)(DF)
BE
(BD)(CD)
(BF)(CF)
BC
AD
AB
(AD)(AF)
(DE)(EF)
AC
DE
EF
BD
CD
(BC)(CE)
(BF)(EF)
AF
BF
CE
l=5
µ=l+2=7
Table 25. Процесс определения ?-порядка КАМСИ.
a1
P,E
P=0
P=1
A
D,0
E,0
B
B,0
C,0
C
A,0
E,0
D
C,1
D,1
E
A,1
B,1
<
3
A
DE
B
BC
C
A
E
D
CD
E
AB
AB
(BD)(BE)
(CD)(CE)
CD
(CE)(DE)
BC
DE
(AC)(AD)
(BC)(BD)
BD
BE
CE
(AE)(BE)
AC
(AD)(AE)
AD
AE
Table 26. Пример построения тестирующей таблицы
P,E
P=0
P=1
A
A,0
E,0
B
D,0
F,0
C
F,1
C,1
D
B,1
E,1
E
C,0
B,0
F
A,1
D,1
P,E1
P=0
P=1
A
A,0
B,0
B
A,1
B,1
P,E
P=0
P=1
AA
AA,0
EA,0
AB
AA,1
EA,1
BA
DA,0
FA,0
BB
DA,1
FA,1
CA
FB,0
CB,0
CB
FB,1
CB,1
DA
BB,0
EB,0
DB
BB,1
EB,1
EA
CA,0
BA,0
EB
CA,1
BA,1
FA
AB,0
DB,0
FB
AB,1
DB,1
P,E
P=0
P=1
A
A,0
I,0
B
A,1
I,1
C
G,0
K,0
D
G,1
K,1
E
L,0
F,0
F
L,1
F,1
G
D,0
J,0
H
D,1
J,1
I
E,0
C,0
J
E,1
C,1
K
B,0
H,0
L
B,1
H,1
Table 27. Пример композиции двух камси.
Информацию-сохранение конечного порядка
Допустим, что система сохраняющих машин используется для кодирования и декодирования. «Кодер» принимает входную последовательность и производит выходную последовательность, которая передается «декодеру». Понятно, что если кодер – информацию сохраняющий, то его входная последовательность может быть восстановлена из выходной последовательности так же хорошо, как и начальное и конечное состояния. Главное отступление в таком процессе заключается в факте, что информация относительно конечного состояния может быть передана кодером только после передачи всей информации. Отсюда следует, что вся информация должна быть записана в буфер перед началом процесса декодирования. Так как передаваемая последовательность может быть произвольно большой, информацию сохраняющая машина не может применяться на практике. С учетом этих ограничений перейдем к рассмотрению машин, для которых нет необходимости буферизовать полную информацию, но где процесс декодирования может начинаться только когда известно начальное состояние и длина входной последовательности.
Определение. 5 Машина называется (информацию) сохраняющей конечного порядка, если знание исходного состояния и первых µ выходных символов достаточно чтобы однозначно определить первый входной символ.
Знание начального состояния и первого входного символа достаточно, чтобы определить следующее состояние и второй входной символ может быть вычислен при использовании (µ+1)-го выходного символа и т.д.. Число µ, которое определяет задержку при декодировании входных символов, является порядком сохранения, если µ есть наименьшее целое, удовлетворяющее приведенному выше определению так, что если для некоторого исходного состояния и последовательности из (µ-1) выходных символов, существует минимум две возможных входных последовательностей, которые отличаются разными значениями исходного входного символа.
Простейший пример информацию содержащей машины конечного порядка – первого порядка, где первый входной символ может быть определен из знания исходного состояния и первого выходного символа. Очевидно, что декодирование производится без задержки для этого класса машин. В качестве примера примем машину Table 5. Поскольку для каждого состояния выход связан 0-преемник по выходу от выхода 1-преемника, знание начального состояния и первого выходного символа достаточно, чтобы определить первый входной символ. Например, если исходное состояние А, и если выход равен 1, то можно однозначно определить, что на вход был подан 0.
PS
NS,z
x=0
x=1
A
C,1
D,0
B
D,0
A,1
C
D,1
B,0
D
C,0
B,1
Table 5
Инверсная (обратная) машина
Определение. 7 Инверсия iM – машина, которая, если она принимает выход машины Мi, то, после конечной задержки, выдает входную последовательность Мi.
Разумеется, определенную выше инверсию iM можно построить только, если Мi информацию сохраняющая и имеет конечную память.
В качестве примера, возьмем машину Table 6а, которая информацию сохраняющая первого порядка. При любом начальном состоянии и любой выходной последовательности, знания начального состояния и первого выходного символа достаточно, чтобы определить первый входной символ. Отсюда видно, что такая машина не имеет задержки при декодировании.
PS
NS,z
x=0
x=1
A
C,1
D,0
B
D,0
A,1
C
D,1
B,0
D
C,0
B,1
PS
NS,x
z=0
z=1
A
D,1
C,0
B
D,0
A,1
C
B,1
D,0
D
C,0
B,1
a)
b)
Table 6
В Table 6b показана инверсная таблица, которая построена, как выходная таблица переходов.
Рассмотрим один из способов восстановления входной последовательности.
Для каждой машины, которая сохраняет информацию µ-порядка, знания состояния в момент t-µ+1 и последних µ
выходных символов последовательности
zt-?+1,zt-?+2,z, … zt достаточно для однозначного определения выходного символа xt+?+1.
Следовательно, если мы передадим выходную последовательность машине Мi µ-порядка на входы регистра, который состоит из µ-1
элементов задержки, мы можем построить комбинационную схему, которая принимает содержимое регистра, так же, как состояние машины Мi
в момент t-µ+1 и вырабатывает значение xt+?+1.
Комбинаторный блок можно задать в виде таблицы истинности, в которой величина xt+?+1 определяется для каждой возможной комбинации из S(t-µ+1) и
zt-?+1,zt-?+2,z, … zt. Информация относительно состояния Мi. может быть передана комбинационной схеме копией оригинальной машины Мi, которая может быть установлена при t=µ-1 в то же самое состояние, в котором Мi
была при t=0, и принято как ее задержанные (при µ-1 задержках) версии входов М. Структурная схема такой декодирующей системы показана на Рис. 7.
Приведенная декодирующая система не совсем экономна, так как требует копии исходной машины и (µ-1)-разрядного регистра ([8]).
Рис. 7
КАМСИ-композиция
В последующих двух разделах (Свойства последовательного соединения КАМСИ и Алгоритм построения КАМСИ-композиции) мы введем операцию построения конечного автомата, эквивалентного последовательно включенным КАМСИ. Такой конечный автомат назван КАМСИ-композицией. Показано, что КАМСИ-композиция сохраняет свойства КАМСИ и приводятся формулы, позволяющие вычислить µ-порядок и число состояний таблицы переходов КАМСИ-композиции.
КАМСИ-композиция и КАМСИ-примитив
Введем несколько определений.
Допустим, существует два примитива ?(i) и ?(j) (i,j:=1,[?]), где ?(i)
и ?(j) – примитивы i
-го и j
–го типов, а [?] - мощность множества ?
примитивов.
Было уже показано, что если две КАМСИ-композиции, каждая из которых состоит из примитивов ?(i) и ?(j), и отличается только порядком расположения примитивов, то они имеют разные таблицы переходов (то есть, реализуют разные алгоритмы).
Если одну из этих КАМСИ-композиций обозначим, как кортеж
то другую можно обозначить:
, где нижний индекс у ? соответствуют позиции примитива в КАМСИ-композиции.
В общем виде, m-позиционные кортежи КАМСИ-композиции можно записать в виде:
Форм. 3
где:
- примитив или его инверсия типа q, который расположен в i-ой позиции кортежа;
q - один из множества ?
примитивов типа q.([23])
Рассмотрим некоторые свойства КАМСИ, которые позволят нам оценить возможное количество кортежей.
Утверждение 8: «Перестановка переходов в любой строке таблицы переходов КАМСИ сохраняет свойство КАМСИ и его тип (?-порядок и число состояний)».
Например, в Table 21 таблицы переходов (a) и (b) получены перестановкой в строке А. Как следует из способа построения тестирующей таблицы (с) (см. «Минимальная инверсная машина», стр. 17), каждому из них соответствует одна и та же тестирующая таблица Table 21(с).
P,E1
P=0
P=1
A
B,0
A,0
B
A,1
B,1
(a)
P,E1
P=0
P=1
A
A,0
B,0
B
A,1
B,1
(b)
Е1,Р
Е1=0
У1=1
A
AB
B
AB
AB
-
-
(c)
?=2
Table 21
Столбец А
Столбец В
P,E1
P=0
P=1
A
B,0
A,0
B
A,1
B,1
P,E1
P=0
P=1
A
B,1
A,1
B
A,0
B,0
000
100
P,E1
P=0
P=1
A
A,0
B,0
B
A,1
B,1
P,E1
P=0
P=1
A
A,1
B,1
B
A,0
B,0
001
101
P,E1
P=0
P=1
A
B,0
A,0
B
B,1
A,1
P,E1
P=0
P=1
A
B,1
A,1
B
B,0
A,0
010
110
P,E1
P=0
P=1
A
A,0
B,0
B
B,1
A,1
P,E1
P=0
P=1
A
A,1
B,1
B
B,0
A,0
011
111
Table 22
Утверждение 9 : « Инвертирование всех значений выходов автомата в таблице переходов КАМСИ сохраняет свойство КАМСИ и его тип».
Например, в Table 22 в столбцах (А) и (В) в строках 000 и 100 расположены таблицы переходов, полученные инвертированием значений выходов, соответственно. Другие строки таблицы получены последовательным применением операций, описанных в «Утверждение 8» и «Утверждение 9».
Таким образом, в Table 22 (в столбце А) приведены все варианты таблицы переходов 000, к которой применена операция, описанная в «Утверждение 8», а столбец В
получен применением к соответствующей таблице переходов столбца А «Утверждение 9».
Если обозначить через n? число состояний примитива, то не трудно показать, что общее число примитивов будет равно
.
Допустим, Библиотека Примитивов состоит только из примитивов, приведенных в Table 22 и их инверсий. Из этого следует, что общее число элементов Библиотеки равно
и это число равно числу вариантов заполнения каждого разряда m-позиционного кортежа.
Не трудно показать, что число m-позиционных кортежей, которые могут быть получены перестановкой с повторением равно
.
Так, для m=10 ,
кортежей, каждый из которых соответствует КАМСИ с ?=2Чm=20, и N=211=2048.
Для примитива, анализируемого в Table 12 (см. стр.23), у которого n?=5 и ?(?)=6, для m=10:
кортежей. Если обратиться к Table 23 (см. стр. 41), то можно увидеть, что это число в 1013
раз больше возраста Вселенной.
Полученные цифры показывают, что даже если использовать только примитив с параметрами n?=5, ?(?)=6, то и этого достаточно, чтобы обеспечить всех желающих сгенерировать пару разных ключей любое количество раз в течение всего времени существования нашей цивилизации без опасности, что результаты генерации когда либо повторятся. Сравнение
с
показывает, что функция
монотонно возрастает с ростом x и y, то есть, полученные оценки можно считать нижней границей при оценке количества кортежей при использовании разных типов примитивов.
В заключение можно утверждать, что, имея набор двух-трех типов примитивов и их инверсий, можно сформировать криптографический алгоритм на базе КАМСИ, при котором:
Отпадает необходимость строить КАМСИ, применяя описанные выше тестирующие процедуры;
Отпадает необходимость обеспечивать секретность Библиотеки Примитивов.
Рассмотрим далее процесс формирования кортежей.
Двоичная запись чисел, поставленных в соответствие примитиву в Table 22, представляет собой шаблон, который показывает, как из примитива с номером 000 (назовем ее базовой ([24])) получить примитив, соответствующий заданному числу.
На это указывает взаимное расположение в этом числе единиц и нулей:
a) Единица в первом (слева) разряде показывает, что в базовой модели следует инвертировать значения выходов во всех состояниях (то есть, применить операцию из «Утверждение 9»);
b) Для остальных разрядов заданного двоичного числа выполнить операцию, описанную в «Утверждение 8» для всех состояний базовой модели, номера которых совпадают с номерами позиций, в которых располагаются единицы.
Например, для компонентов типа (n?=2, ??=2) кортеж 101, 011, 111, 000, 000, 110, 001 (см. Table 22, стр. 37), который можно представить в виде: 5370061 (восьмеричная запись). Этот кортеж соответствует КАМСИ-композиции (m=7, µ=14), в которой примитивы расположены в порядке, описанном выше.
Таким образом, приведенные «Утверждение 8» (стр. 36) и «Утверждение 9» (стр. 37) позволяют построить кортеж
для КАМСИ-композиции. Для этого достаточно выбрать (можно с повторениями) m
компонентов из таблицы, подобной Table 22.
Конечные автоматы, сохраняющие информацию
Следующие разделы, включая раздел «Минимальная инверсная машина» (см.стр. 16) написан на основе материалов, опубликованных в книге Zvi Kohavi, Switching and Finite Automata Theory, Second Edition 1978, Memory, Definiteness, and Information Lossless ness of Finite Automata chat. 14, pp. 507.
Важная характеристика конечного автомата (КА) – наличие “памяти”, т.е. поведение Машины ([5]) определяется ее историей.
Поведение одних машин может зависеть от большего числа предшествующих событий, а других – от меньшего.
Определение. 1 Количество информации о входах и выходах, необходимое для определения будущего поведения машины, называется диапазоном памяти машины.
Известно, что если для конкретной машины определено начальное состояние и известна входная последовательность, то это однозначно определяет выходную последовательность и конечное состояние. Однако, существует ситуация, при которой неизвестно начальное состояние или некоторое число предыдущих входных значений. В такой ситуации поведение машины не всегда может быть предсказанным. Мы попробуем ответить на вопрос: а) для данной машины определить минимум информации о входах-выходах, необходимый для определения будущего поведения машины. б) При каких условиях можно восстановить входную последовательность по выходной?
в Table 2а, соответствует предельному
Машина M2 показанная в Table 2а, соответствует предельному значению µ.
PS
NS,z
x=0
x=1
A
B,0
D,0
B
C,0
C,0
C
D,0
A,0
D
D,0
A,1
a)
0/0
0/1
1/1
1/0
A
B
-
-
D
B
C
-
-
C
C
D
-
-
A
D
D
-
A
-
AB
BC
-
-
CD
AC
BD
-
-
AD
AD
BD
-
-
-
BC
CD
-
-
AC
BD
CD
-
-
-
CD
DD
-
-
-
b)
Table 2
Соответствующая тестирующая таблица и граф показаны в Table 2b и Рис. 2, соответственно. Как это видно, тестирующий граф свободен от циклов и максимальный путь, начинающийся в АВ и оканчивающийся в CD, имеет длину 5. Отсюда µ=6. В общем, можно показать, что существует класс машин, для которых µ=(n-1)n/2.
Рис. 2
Машины, сохраняющие информацию
Одна из центральных проблем в кодировании и передаче информации есть определение условий, при которых возможно восстановить входную последовательность машины из соответствующей выходной последовательности. Будет показано, что всякий раз, когда машина используется, как кодирующее устройство и когда начальное и конечные состояния известны, ее информационная сохраняемость гарантирует, что полученное сообщение может быть всегда декодировано.
Определение. 4 Можно определить машину М как информацию сохраняющую, если известное начальное состояние, выходная последовательность и конечное состояние достаточны для однозначного определения входной последовательности.
Минимальная инверсная машина
Мы продемонстрируем процедуру построения минимальной инверсии на примере М показанной в Table 7а. Эта машина третьего ?-порядка (µ=3), поэтому, если мы знаем исходное состояние и значения трех
соответствующих выходных символов при переходах из начального состояния, мы можем определить первый входной символ. Определим множество триплов, обозначая их: S(t)zt+1,zt+2.
Первый компонент каждого трипла (S(t)) есть любое из исходных состояний машины М, второй (zt+1) – один из выходных символов, который может быть продуцирован при одном из переходов из этого состояния и третий (zt+2) –выходной символ, который может быть продуцирован при переходе из этого состояния. Трипл определяется для каждого возможного исходного состояния и для всех возможных последовательностей длиной 2. Для машины М
полученные триплы показаны в Table 7c. Из этой таблицы видно, что, например, трипл (А,0,1) - не определен, потому, что, если исходное состояние А, то после нулевого значения на выходе (переход А=>C), следующим значением не может быть единица.
Множество так сгенерированных триплов содержит все возможные варианты начальных состояний и соответствующих им выходных последовательностей длиной 2. Чтобы определить входной символ, который явился причиной перехода из этого начального состояния, при котором вырабатывается на выходе символ, определенный вторым
компонентом трипла, требуется еще один дополнительный выходной символ. Следовательно, если мы создаем машину, у которой каждое состояние соответствует триплу и представляет «информацию», содержащуюся в трипле, и если мы получим машину с выходами исходной машины, тогда мы получим всю необходимую информацию, необходимую для вычисления исходных символов.
Перейдем к построению таблицы переходов инверсной машины. Для этого обозначим инверсную машину через *М, которая, в соответствии с примером имеет 8 состояний, соответствующих восьми триплам (см. Table 7c).
Начнем построение таблицы переходов машины *М.
Она соответствует автомату, на входы которого подаются биты z, а на выходе формируются сигналы x.
Такая таблица имеет три столбца: PS, z=0, z=1.
Приступим к заполнению таблицы. Для этого:
Переписать в первый столбец построенные нами триплы из Table 7с.
Для строки (A,0,0) в столбце z=0 строим трипл:
Первый элемент трипла: С – название состояния, в которое перейдет машина из А при х=0.
Второй элемент трипла – 0, - это второй компонент трипла (A,0,0).
Третий элемент трипла - значение выхода (z), соответствующее значению z=0
столбца *М.
Значение выхода машины *М, равное значению х, при переходе А=>C. Получаем трипл (С,0,0),0
В этой же строке в столбце z=1:
Первый элемент трипла: С - название состояния, в которое перейдет машина из А при х=0.
Второй элемент трипла – 0, - это второй компонент трипла (A,0,0).
Третий элемент трипла - значение выхода (z), соответствующее значению z=1
столбца *М.
Значение выхода машины *М, равное значению х, при переходе А=>C. Получаем трипл (С,0,0),0. Получаем (С,0,1),0
Таблица состояний машины *М приведена в Table 7b.
Допустим, например, что *М находится в состоянии (A,0,0) и текущее значение входа – 0. Чтобы определить его 0-преемник мы увидим, что машина М, если она находится в состоянии А,
PS
NS,z
x=0
x=1
A
C,0
D,1
B
D,0
С,1
C
А,0
B,0
D
C,1
D,1
PS
NS,x
z=0
z=1
(A,0,0)
(C,0,0),0
(C,0,1),0
(A,1,1)
(D,1,0),1
(D,1,1),1
(B,0,1)
(D,1,0),0
(D,1,1),0
(B,1,0)
(C,0,0),1
(C,0,1),1
(C,0,0)
(A,0,0),0
(B,0,1),1
(C,0,1)
(B,1,0),1
(A,1,1),0
(D,1,0)
(C,0,0),0
(C,0,1),0
(D,1,1)
(D,1,0),1
(D,1,1),1
a)
b)
(A,0,0)
(B,0,1)
(C,0,0)
(D,1,0)
(A,1,1)
(B,1,0)
(C,0,1)
(D,1,1)
c)
Table 7
может продуцировать три последовательных нуля на выходе только если первый входной символ есть 0; как результат, первый переход *М есть состояние С и первый компонент трипла 0-преемника из (A,0,0) есть С.
Второй компонент трипла равен третьему компоненту трипла (A,0,0), а его третий компонент - это текущее значение выхода М, который, в действительности, является входом в *М и записанный в заголовке ее
таблицы переходов. Выход *М - это задержанный выход на вход М; так что выход *М в момент t равен ее входу в момент t-2.
Множество состояний, сгенерированных в виде множества триплов определяет ее таблицу переходов для реализации инверсной машины. Это не просто множество состояний. Машина *М, например, может быть упрощена, так как (A,0,0) эквивалентно (D,1,0) и (A,1,1) эквивалентно (D,1,1). Если обозначить через S1 (A,0,0), S2 - (A,1,1) и т.д., то мы получим минимальную таблицу инверсии, показанную в Table 8.
PS
NS,z
z=0
z=1
S1
S5,0
S6,0
S2
S1,1
S2,1
S3
S1,0
S2,0
S4
S5,1
S6,1
S5
S1,0
S3,1
S6
S1,1
S3,0
Table 8
Рассмотренная процедура применима для любой информацию сохраняющей машины конечного порядка. В общем, для машины порядка µ, мы определим множество µ-кортежей, которые образуют множество состояний инверсии. Первый элемент каждого µ-кортежа – состояние М; остальные элементы – возможные выходные последовательности длиной, равной µ-1, которые могут быть произведены при последующих переходах из этого состояния. Очевидно, что эта процедура выдает более экономичную реализацию, чем приведенная на Рис. 7, так как в ней мы запоминаем выходную последовательность в сдвиговом регистре и использовать копию М, чтобы определить состояние в исходной М.
Допустим, что М (Table 7b) находится в начальном состоянии и в ответ на некоторую входную последовательность она продуцирует одну из последовательностей 00 или 11. Тогда *М двумя шагами позднее должна быть в состоянии, которое соответствует А и соответствующую выходную последовательность, то есть (А,0,0) или (А,1,1). Но поскольку S4: (B,1,0) единственное состояние, из которого *М может достигнуть (А,0,0) и (А,1,1), когда будет подан на вход 00 и 11, соответственно. Из этого следует что, если начальное состояние М есть А, то начальное состояние *М должно быть (В,1,0). Не трудно убедиться, что если М находится в состоянии В, то *М может быть либо в состоянии S1 либо в состоянии S4, и когда М находится в состоянии С или D, М* может находиться в одном из состояний S2, S3, S5 или S6.([9])
Как пример, демонстрирующий декодирующие свойства *М, допустим, что М и *М находятся в состоянии А и S4, соответственно, и допустим, что на вход М подана последовательность 010001101. Процесс кодирования-декодирования показан в Table 9.
Состояние М
A
С
B
D
C
A
D
D
C
B
Вход М
0
1
0
0
0
1
1
0
1
Выход М
0
0
0
1
0
1
1
1
0
Состояние М*
S4
S5
S1
S5
S3
S1
S6
S2
S2
S1
Выход М*
-
-
0
1
0
0
0
1
1
Table 9
Первые два символа в начале и в конце следует игнорировать. В оставшихся позициях, обе последовательности, входная для М и выходная для М* - идентичны, хотя сдвинуты во времени.([10])
Некоторые операции преобразования КАМСИ
В этом разделе вводятся понятия КАМСИ-композиции и КАМСИ-примитивов. Показано, что если КАМСИ-композиция (кодер) состоит из n КАМСИ-примитивов, то легитимная
сложность инвертирования кодера линейно зависит от n.
Вводятся преобразования КАМСИ-примитивов, которые сохраняют свойства КАМСИ и доказано, что композиция КАМСИ так же сохраняет свойство КАМСИ.
Обсуждение возможности построения однонаправленной функции с «секретом».
Рассмотрим пример.
В Table 12 в строке 1 приведена сложность инвертирования КАМСИ-примитива с n=5, а в строке 2 – сложность инвертирования композиции двух примитивов, каждый из которых имеет n=5 состояний. Как следует из таблицы, сложность инвертирования этой композиции (таблицы переходов с 25 состояниями) составляет ?224
операций.
Если же мы вначале инвертируем два КАМСИ-примитива, а затем выполним композицию их инверсий (сложность инвертирования каждого примитива ?212), то сложность построения инверсной КАМСИ будет равна 2•212= ?
213 (проще в
211 раз).
224 и 213 разница ощутимая, но - в пределах технических возможностей компьютера. Но вот, если обратиться к 5 строке Table 12 (композиция пяти примитивов – таблица переходов состоит из 1250 состояний), то здесь сложность инвертирования композиции пяти КАМСИ-примитивов будет равна ?260, в то время, как инвертирование пяти примитивов будет равно 5•212=1.25•214. то есть, сложность инвертирования композиции пяти КАМСИ-примитивов в ?246 раз больше раздельного инвертирования пяти КАМСИ-примитивов.
Оценим, как изменяется отношение сложности инвертирования КАМСИ-композиции m примитивов к сложности последовательности примитивов, каждый из которых имеет ?(m)-порядок. Обозначим его - ?(m,?(m)),.
Ранее было показано, что сложность инвертирования КАМСИ, с порядком, равным ?, равна
.
Если примем, что все ?(i)-порядки одинаковые и равны ?(m), то
.
При последовательном инвертировании примитивов
В этом случае сложность инвертирования КАМСИ-композиции превышает сложность последовательного инвертирования m примитивов в:
раз.
Таким образом, если воспользоваться для инвертирования композицией наборов из m компонентов, то удастся упростить процесс инвертирования в
раз.
Это дает возможность построить на базе КАМСИ-композиции однонаправленную функцию с «секретом».
«Секрет» заключается в том, что тот, кто выбрал КАМСИ-компоненты и построил КАМСИ-композицию, получает возможность упростить в
раз построение инвертора кодера.
Теперь любой участник информационного процесса, имея инверсию композиции КАМСИ-примитивов, может закодировать информацию, а раскодировать ее сможет только единственный обладатель композиции КАМСИ-примитивов (вот он «секрет» однонаправленной функции!), то есть, обладатель кода. В это же время, любой, кто пожелает раскодировать информацию, должен будет инвертировать открытый ключ, выполнив (для рассмотренного примера) ?260?1018
операций, так как ему не известен порядок, в котором примитивы входят в композицию закрытого кода ([18]).
Для того, чтобы представить себе величину 1018, достаточно вспомнить (см. Table 23, см. Дополнение, стр. 41 ), что возраст Вселенной составляет всего 1010
лет.
Table 12 показывает, что сложность инвертирования резко возрастает при линейном росте m – кратности (то есть, количества) КАМСИ-примитивов в композиции.
Таким образом, «секретом» однонаправленной функции является набор и порядок следования примитивов в композиции - закрытом ключе.
В Table 21 приводятся значения ?(m,?(m)) в зависимости от m,
изменяющегося в диапазоне 1 .. 7, и ?(m) - в диапазоне 2 .. 5. Из этой таблицы видно, что уже при ?(10)=5 сложность инвертирования КАМСИ-композиции при покомпонентном инвертировании может быть уменьшена в ?(7,5)?1018 раз.
В этом случае: ?=m?(7)=7•5=35, и, в то время, как сложность непосредственного инвертирования равна 270?1021 (сравните с числами в Table 23, строка 4), покомпонентное инвертирование имеет сложность 7•210=71680. Другими словами, обладатель «секрета» (знание структуры декомпозиции кодера) получает возможность упростить процесс построения инвертора в ?1021 раз.
Приведенный пример еще раз показывает, что на базе КАМСИ-композиции можно построить однонаправленную функцию с «секретом».
m
?(m,2)
?(m,3)
?(m,4)
?(m,5)
1
1
1
1
1
2
8
32
128
512
3
85.3
1395.3
21845.3
349525.3
4
1024
65536
4194304
268435456
5
13107.2
3355443.2
858993459.2
219902325555.2
6
174762.6
178956970
183251937962
187649984473770
7
?107
?1011
?1014
?1018
<
Table 20
Известно, что проблема «взлома» криптографической системы с открытым ключем сводится к «взлому» открытого ключа, то есть построение по нему закрытого, секретного ключа. В роли открытого ключа для криптографической системы на базе КАМСИ выступает инверсия композиции примитивов, образующих кодер.
Перед нелегитимным участником информационного процесса встает проблема дешифрования закодированного сообщения. Этого можно достигнуть одним из способов: либо
1. Инвертировать открытый ключ, или
2. разложить открытый ключ на примитивы, а затем построить композицию секретного ключа, инвертировав полученные компоненты.
Мы уже обсуждали оценку сложности инвертирования (см. Форм. 1, стр. 23) из которой видно, что она зависит от ?-порядка, и, практически, не зависит от числа состояний таблицы переходов инвертируемой КАМСИ.
Для того, чтобы обсуждить проблемы, связанные с декомпозицией открытого ключа, рассмотрим основные этапы построения асимметрического криптографического алгоритма на базе КАМСИ.
Примем, что:
a. Существует абонент А, который строит: а) открытый ключ, с помощью которого абонент В
сможет кодировать сообщения для абонента А, и б) закрытый (секретный) ключ, который будет известен только А, и, с помощью которого абонент А
сможет декодировать сообщение абонента В. «Открытость» системы заключается в том, что в качестве абонента В могут выступать любые абоненты информационной системы, желающие послать сообщение абоненту А, а в качестве абонента А
выступает единственный абонент, «хозяин», который имеет закрытый (секретный) ключ.
b. Всех абоненты информационной сети имеют Библиотеку Примитивов, из которых любой абонент может создать собственный открытый и закрытый ключ.
c. Библиотека Примитивов содержит таблицы переходов примитивов и их инверсий.
С учетом принятого, процесс формирования асимметрического алгоритма можно представить в виде последовательности следующих операций:
1. Выбрать m - количество компонентов КАМСИ-композиции.
2. Выбрать типы КАМСИ-примитивов и порядок их размещения в КАМСИ-композиции секретного ключа. Допускается применение нормальных и инверсных форм примитивов, а так же повторение типов. Единственное ограничение – один и тот же тип не должен входить в набор нормально и инверсно.
3. Построить композицию выбранных компонентов, которая образует секретный ключ. Это секретный ключ ?(m) абонента, который хранится у получателя информации абонента А.
4. Образовать кортеж из инверсий, выбранных в п.2 примитивов, и разместить их в порядке, обратном размещению их в кортеже п.2.
5. Построить композицию из выбранных в п.4 примитивов, образовав КАМСИ-композицию ?(m). ?(m) является открытым ключем;
6. Разослать всем абонентам сети В
открытый ключ ?(m) по незащищенному информационному каналу.
Обратим внимание, что если открытый ключ ?(m),
может распространяться любым способом, в том числе, по незащищенным информационным каналам, то для ?(m),
за все время существования построенного криптографического алгоритма, не возникает необходимость передавать его, либо сообщать его кому бы то ни было.
Проанализируем, возможности «взлома» подобного алгоритма.
Для этого перечислим данные, которыми располагает любой, легитимный и нелегитимный участник информационного процесса:
Количество состояний N таблицы переходов КАМСИ ?(m).
?-порядок ?(m). Эту информацию он может получить, экспериментируя с ?(m).
Библиотеку Примитивов и их инверсий.
Перед «взломщиком» стоит задача определить ?(m).
«Взломщик» может выбрать одну из двух стратегий «взлома»:
1. Инвертировать ?(m), для которой известен ?-порядок ([19]). Эта ситуация рассматривалась нами выше и для нее получена оценка числа операций, равная ? ? 22? (см.Форм. 1, стр. 23 ). Эту стратегию «взлома» взломщик выбирает с учетом своих технических ресурсов.
2. В соответствии с «Утверждение 6» (см. стр. 30) набор примитивов, теоретически, можно определить, решив диофантовы уравнения:
и
,
значения N и ? – можно считать известными, кроме того, возможные значения ni
и ?(i) можно определить из Библиотеки Примитивов (способ построения Библиотеки будет определен ниже)
Несмотря на сложность решения этих уравнений, проблема будет решена частично, так как после этого остаются неизвестными:
порядок следования компонентов, и
форма примитива (нормальная или инверсная) выбраная при формировании ?(m) ([20]).
Что же такое примитивы?
Достаточно ли их количество, чтобы строить на их основе секретные криптографические ключи ([21])?
Это обстоятельство очень важно.
Действительно, если окажется, что примитивы существуют в малом количестве, то при определении кортежа ([22]) композиции (числа и порядка расположения примитивов в композиции) пространство перебора будет настолько ограниченным, то есть пространство перебора будет малым.
Оценка количества операций при криптоанализе асинхронного алгоритма на базе КАМСИ.
Примем, что при анализе асинхронного криптографического алгоритма на базе КАМСИ, криптоаналитику (легитимному или нелегитимному - «взломщику») известна таблица переходов открытого ключа ?, содержащая N состояний, значение ее ?-порядка и Библиотека Примитивов с их инверсиями.
Цель криптоанализа – построить КАМСИ ? (закрытый ключ), обратный открытому ключу ?.
Чтобы построить КАМСИ ? (закрытый ключ), криптоаналитик,
a) либо инвертирует ?, сложность вычисления которой равна ?22?, либо
b) строит кортеж для ?. Этот процесс распадается на следующие операции:
ь генерация множества кортежей из компонентов Библиотеки Примитивов;
ь построение композиции КАМСИ для каждого кортежа; и
ь проверка построенной композиции на эквивалентность ее с ?.
Какую из этих стратегий следует выбрать?
Для стратегии (a) сложность выполнения известна и равна ?22?.
Для сравнения этих стратегий, оценим сложность выполнения стратегии (b).
Для этого необходимо для известного ?
определить:
размерность m порождающего его кортежа;
набор примитивов, формирующих кортеж; и
расположение примитивов в кортеже (см. Форм. 3, стр. 35).
Оценка сложности определения ?-порядка кодера
В разделе «Минимальная инверсная машина» (см. стр.17) показан процесс определения ?-порядка таблицы переходов.
Определим сложность построения тестирующей таблицы и тестирующего графа.
Оценка сложности построения инверсного автомата.
В последующих двух разделах рассмотрен процесс оценки сложности построения инверсного автомата.
Оценка сложности построения таблицы ?-кортежей
В разд. «Минимальная инверсная машина»(см. стр. 17) введено понятие ?-пла (мюпла), который далее будем называть ?-кортежем. ?-кортеж представляет собой последовательность значений на выходе последних ? переходов, первый из которых появляется при переходе из заданного состояния КАМСИ.
PS
NS,z
x=0
x=1
A
C,0
D,1
B
D,0
С,1
C
А,0
B,0
D
C,1
D,1
(a)
A
B
C
D
00
+
+
01
+
+
10
+
+
11
+
+
(b)
PS
NS,x
z=0
z=1
S0
(A,0,0)
(C, 0,0),0
(C, 0,1),0
S1
(A,0,0)
(C,0,0),0
(C,0,1),0
S2
(A,1,1)
(D,1,0),1
(D,1,1),1
S3
(B,0,1)
(D,1,0),0
(D,1,1),0
S4
(B,1,0)
(C,0,0),1
(C,0,1),1
S5
(C,0,0)
(A,0,0),0
(B,0,1),1
S6
(C,0,1)
(B,1,0),1
(A,1,1),0
S1
(D,1,0)
(C,0,0),0
(C,0,1),0
S2
(D,1,1)
(D,1,0),1
(D,1,1),1
(c)[11]
PS
NS,x
z=0
z=1
S0
S5,0
S6,0
S1
S5,0
S6,0
S2
S1,1
S2,1
S3
S1,0
S2,0
S4
S5,1
S6,1
S5
S1,0
S3,1
S6
S4,1
S2,0
(d)
P
0
0
1
0
1
1
0
0
1
1
1
0
0
Au
A
C
A
D
C
B
C
A
C
B
C
B
D
C
E
0
0
1
1
0
1
0
0
0
1
0
0
1
SS
S0
S5
S1
S6
S2
S1
S6
S4
S5
S1
S6
S4
S5
S3
P
0
0
0
0
1
0
1
1
0
0
1
1
1
(e)
P
0
0
1
0
1
1
0
0
1
1
1
0
0
SS
S0
S5
S1
S6
S4
S6
S2
S1
S5
S3
S2
S2
S1
S5
E
0
0
0
1
1
0
1
0
1
0
1
1
0
Au
A0
C
A
C
B
C
A
D
C
B
D
D
D
C
P
0
0
0
0
1
0
1
1
0
0
1
1
1
<
(f)
Table 11
Построим таблицу ?-кортежей, которая состоит из 2? строк и N столбцов. Для заполнения клетки таблицы, которая расположена в j-ой строке и p-ом столбце следует проверить, существует ли переход из p-го
состояния, который порождает j-ый ?-кортеж на выходе кодирующего КАМСИ. Если кортеж существует, то соответствующую клетку необходимо отметить (в Table 11(b) клетка отмечена крестиком, см. стр. 23).
Не трудно показать, что для заполнения одной клетки таблицы следует проверить ? переходов, и, учитывая, что общее число клеток равно N•2?, общее число операций, которые необходимо выполнить равно ?=N•?•2?.
Кратн.
Комп.
Число сост. табл. перех.
N
Число операций опр.
?-порядка
?
Число опер. заполн. табл. корт. инверт.
?=N?2?
Общ. число опер. для постр. инверт.
2?•(3N + 2?)
a
b
c
d
e
f
h
1
5
?25
6
?211
?211
?212
2
25
?210
12
?222
?222
?224
3
125
?215
18
?229
?229
?236
4
250
?217
24
?236
?236
?248
5
1250
?221
30
?245
?245
?260?1018
6
6250
?226
36
?253
?253
?272?1022
7
31250
?231
42
?262
?262
?284?1025
8
156250
?235
48
?270
?270
?296?1029
ПРИМЕЧАНИЕ. В таблице приведен пример оценки числа операций для КАМСИ, заданного таблицей переходов с пятью состояниями (первая строка). В строках 2 .. 8 приведены значения для композиции автоматов (см. ниже)
Table 12
В Table 12 в столбцах (d,e) показано, как изменяется сложность построения таблицы ?-кортежей (?, ? = N?2?) в зависимости от ?.
Так как конечной целью построения таблицы ?-кортежей является построение таблицы переходов инверсного автомата, то оценим сложность построения таблицы переходов инверсного автомата. Число строк в такой таблице равно числу заполненных клеток в таблице ?-кортежей (см. выше). Не трудно показать, что оно ?2?.
Оценим величины компонентов, из которых складывается сложность построения таблицы переходов для инверсного автомата:
заполнение таблицы кортежей. Для этого следует выполнить ?=N•?•2? операций;
заполнение трех столбцов таблицы переходов – если принять, что в Table 11b заполнены все клетки, то общее число заполнений будет равно 3•N•2? операций (первый столбец – ?-плы, соответствующие состояниям, из которых выполняется переход; второй и третий столбцы - ?-плы, соответствующие состояниям, в которые может быть переход);
проверка ?-плов, второго и третьего столбца, находятся ли они в первом столбце, если нет, то замена их на другие. Общее число таких проверок («каждый с каждым») 2?•2?=22?.
Общее число операций:
? = 3•N•2? +22? = 2?•(3N + 2?) ? 22? Форм. 1
В Table 12(h) показана сложность построения обратного автомата.
Из приведенной таблицы можно сделать несколько выводов:
ь Сложность построения инвертора одинакова для легитимного и нелегитимного участника информационного обмена, то есть, криптографический процесс на базе информацию сохраняющей машины представляет собой однонаправленную функцию «без секрета». Этим обстоятельством можно объяснить факт, что на возможности применения для криптографии Информацию Сохраняющих Машин еще за двадцать лет до появления RSA они до сих пор не нашли применения.
ь При значениях ? ? 30 (? ? 260 ?1018) задача построения инвертора становится технически невыполнимой.
Оценка сложности построения тестирующей таблицы.
В Table 10 (см. стр. 21) показан процесс тестирования. В Table 10(а) показана таблица переходов, которую следует проверить, во-первых, на информационную сохраняемость (то есть, является ли она КАМСИ) и, если таблица отвечает этим условиям, то, во-вторых, определить ее µ-порядок.
Table 10(b) – это тестирующая таблица, которая состоит из двух половин
a) верхняя половина, которая состоит из N строк, и
b) нижняя половина, количество строк в которой содержит число строк, не превышающее число сочетаний из N по 2, равное
;
c) учитывая, что для заполнения каждой строки нижней части таблицы требуется 4 операции, общее число операций при заполнении таблицы, равно
.
Например, для КАМСИ Table 10(a) приведены параметры, характеризующие сложность определения ?-порядка, который в рассматриваемом случае равен 7.
a1
P,E
P=0
P=1
A
A,0
E,0
B
D,0
F,0
C
F,1
C,1
D
B,1
E,1
E
C,0
B,0
F
A,1
D,1
N=6
(a)
a1
P,E
P=0
P=1
A
AE
B
DF
C
CF
D
BE
E
BC
F
AD
AE
(AB)(AC)
(DE)(EF)
DF
(AB)(BD)
(AE)(DE)
CF
(AC)(CD)
(AF)(DF)
BE
(BD)(CD)
(BF)(CF)
BC
AD
AB
(AD)(AF)
(DE)(EF)
AC
DE
EF
BD
CD
(BC)(CE)
(BF)(EF)
AF
BF
CE
(b)
(c)
l=5
µ=l+2=7
Table 10
Однонаправленная функция
(по материалам http://cryptor.narod.ru/glava4/glava4_2.html)
Концепция асимметричных криптографических систем с открытым ключом основана на применении однонаправленных функций. Неформально однонаправленную функцию можно определить следующим образом.
Пусть Х
и Y - некоторые произвольные множества.
Функция f: X ® Y является однонаправленной, если для всех хОХ
можно легко вычислить функцию y=f(x), где yОY. И в то же время для большинства yОY
достаточно сложно получить значение хОХ, такое, что f(x)=y (при этом полагают, что существует по крайней мере одно такое значение х).
Основным критерием отнесения функции f к классу однонаправленных функций является отсутствие эффективных
алгоритмов обратного преобразования Y®X.
В качестве первого примера однонаправленной функции рассмотрим целочисленное умножение. Прямая задача - вычисление произведения двух очень больших целых чисел Р
и Q, т.е. нахождение значения N = P • Q, является относительно несложной задачей для ЭВМ.
Обратная задача - разложение на множители большого целого числа, т.е. нахождение делителей Р
и Q большого целого числа N = P • Q, является практически неразрешимой задачей при достаточно больших значениях N. По современным оценкам теории чисел при целом N»2664
и соизмеримых значениях P и Q,
для разложения числа N
потребуется около 1023
операций, т.е. задача практически неразрешима на современных ЭВМ.
Еще один пример однонаправленной функции - это модульная экспонента с фиксированными основанием и модулем. Пусть А и N - целые числа, такие, что 1ЈА<N.
Определим множество ZN, как ZN= {0,1,2,…,N-1 }.
Тогда модульная экспонента с основанием А
по модулю N представляет собой функцию
fA,N: ZN > ZN такую, что fA,N(x)= Ax(mod N)
где x-целое число, 1Ј x Ј N-1.
Существуют эффективные алгоритмы, позволяющие достаточно быстро вычислить значения функции fA,N(x). Если y=Ax, то естественно записать x=logA(y).
Поэтому задачу обращения функции fA,N(x) называют задачей нахождения дискретного логарифма или задачей дискретного логарифмирования.
Задача дискретного логарифмирования формулируется следующим образом. Для известных целых A, N, у
найти целое число х,
такое, что Ax(mod N)=y.
Алгоритм вычисления дискретного логарифма за приемлемое время пока не найден. Поэтому модульная экспонента считается однонаправленной функцией.
По современным оценкам теории чисел при целых числах А»2664
и N»2664
решение задачи дискретного логарифмирования (нахождение показателя степени х
для известного у) потребует около 1026
операций, т.е. эта задача имеет в 103
раз большую вычислительную сложность, чем задача разложения на множители. При увеличении длины чисел разница в оценках сложности задач возрастает.
Следует отметить, что пока не удалось доказать, что не существует эффективного алгоритма вычисления дискретного логарифма за приемлемое время. Исходя из этого, модульная экспонента отнесена к однонаправленным функциям условно, что, однако, не мешает с успехом применять ее на практике.
Вторым важным классом функций, используемых при построении криптосистем с открытым ключом, являются так называемые однонаправленные функции с "с секретом".
Дадим неформальное определение такой функции.
Определение. 8 Функция f: X ® Y относится к классу однонаправленных функций с "секретом" в том случае, если она является однонаправленной и, кроме того, возможно эффективное вычисление обратной функции, если известен "секрет" (секретное число, строка или другая информация, ассоциирующаяся с данной функцией).
В качестве примера однонаправленной функции с "секретом" можно указать используемую в криптосистеме RSA модульную экспоненту с фиксированными модулем и показателем степени. Переменное основание модульной экспоненты используется для указания числового значения сообщения P либо криптограммы E.
Приведенное позволяет заключить, что на базе описанных выше Машин, Сохраняющих Информацию можно построить однонаправленную функцию, так как при этом будет создан алгоритм кодирования, в котором для кодирования и декодирования применяются разные алгоритмы. Тем не менее, полученная однонаправленная функция будет иметь одинаковую сложность построения обратной функции для всех участников информационного обмена, то есть, такая однонаправленная функция не буде обладать «секретом».
Определение состояния машины
Если машина имеет конечную выходную память, то, возможно, определить состояние М в некоторой точке эксперимента длиной µ. Мы теперь увидим, как определить это состояние, когда известна только информация о выходной последовательности.
Допустим, например, что выходная последовательность производится машиной Table 3а.
Примем, что выходная последовательность есть 1110. Так как на выходе 1, то это означает, что переход может быть из одного из состояний А,
В или D, состояние С
здесь не подходит. Это значит, что первоначальная неопределенность есть (АВD). Из Table 3b находим, что выходные 1-наследники: из А – D, из В – (АС), из D – С. Следовательно, 1-наследник (АВD) есть (АСD). Результат последующего приведен в Table 4.
Возможная неопределенность
A
B
D
A
C
D
C
D
C
B
C
Выходная последовательность
1
1
1
0
Table 4
Следует обратить внимание, что хотя состояние было идентифицировано в течение эксперимента, неопределенность понизилась до (ВС).
Идентификация некоторой точки в течение эксперимента не может гарантировать идентификацию преемника. Можно сказать, что внутри µ передача любой выходной последовательности, может быть минимум один период, в течение которого машина может однозначно находиться в определенном состоянии, в зависимости от исходного состояния ([7]).
Отношение размера памяти с входной - выходной последовательностью (машины с конечной памятью - МКМ)
Определение. 2 Машина с конечной памятью М называется машиной с конечной памятью µ-порядка, если µ есть наименьшее целое, такое что текущее состояние М может быть определено однозначно из последних µ значений входов и µ выходов.
Другими словами, машина есть МКМ, если и только если каждая входная последовательность длинной µ
является установочной последовательностью. Соответственно, установочное дерево может служить инструментом для обнаружения и определения конечной памяти для М. В этом разделе мы определим различные тесты достаточные для определения всех аспектов памяти автомата.
Проблема определения размерности m кортежа при криптоанализе
В соответствии с «Утверждение 6» (см. стр. 30) известные криптоаналитику N и ?-порядок связаны со значением m зависимостями:
(а)
и
(в)
:
Так как при формировании кортежа применяются не только примитивы, но и их инверсии, то значения ni не всегда простые числа, поэтому, разложение N на сомножители не позволяет определить m. Кроме того, остается неизвестным размещение компонентов в кортеже, а, как было показано выше, два кортежа одинаковой размерности и с одинаковыми компонентами, но отличающиеся размещением компонентов, соответствуют разным КАМСИ.
Мы уже упоминали, что Библиотека содержит примитивы и их инверсии.
В этом случае общее число компонентов в Библиотеке равно:
, где ? – общее число типов примитивов в Библиотеке.
Общее число кортежей размерностью m равно количеству размещений m с повторением из ?:
Форм. 4
Как было показано выше, криптоаналитик не знает m – размерность кортежа, поэтому он должен провести эксперименты, начиная с кортежа, размерностью 2 и больше, до тех пор, пока не обнаружит кортеж, соответствующий ?. Общее число сгенерированных кортежей будет равно:
Для рассмотренного выше примера Библиотеки примитивов с ?=2: n1=2, n2=5 и m=8, значение ??
равно:
кортежей.
Как видно из приведенного, число ??
?1023 значительно меньше сложности инвертирования, приведенной в Table 12 (см. стр. 23), которая равна 1029. Тем не менее, здесь возникает проблема «остановки» процесса генерации. Это обстоятельство требует для каждого из 1023
кортежей выполнять две операции:
строить таблицу переходов КАМСИ-композиции, соответствующей сгенерированному кортежу; и
проверить полученную КАМСИ-композицию на эквивалентность с открытым ключем ?. Сложность этой операции соизмерима с операцией инвертирования КАМСИ.
«Секреты» однонаправленной функции (trap-door funcnion) на базе КАМСИ
Прежде чем рассматривать построение однонаправленной функции с «секретом» на базе КАМСИ введем некоторые их преобразования
Ширина памяти относительно последовательностей вывода
Конечно-автоматная машина М
имеет ширину памяти порядка µ, если µ есть наименьшее целое, такое, что знание последних µ значений выхода позволяет определить состояние, в котором находилась М
в течение последних µ
транзакций. В этой секции основной упор будет сделан на определение состояния М в течение времени эксперимента, вместо определения конечного состояния. Случай определения конечного состояния более узкий и может быть рассмотрен читателем самостоятельно.
Список литературы
1. Lui, C. L.: Some Memory Aspects of Finite Automata, M.I.T.Rcs. Lab. Electron. Tech. Rept. 411, May, 1963.
2. Lui, C. L.: Determination of the Final State of an Automaton Who’s Initial State Is Unknown, IEEE Trans. Electron. Computers, vol. EC-12, December, 1963.
3. Lui C. L.: kth-order Finite Automaton, IEEE Trans. Electron. Computers, vol. EC-12, October, 1963.
4. Massey, J. L.: Note on Finite Automaton Sequential Machines, IEEE Trans. Electron. Computers, vol. EC-15, pp. 658-659, 1966.
5. Simon, S.M.: A Note on Memory Aspects of Sequence Transducers, IRE Trans. Circuit Theory, vol. CT-6, Special Supplement, pp. 26-29, May, 1959.
6. Perles, M., M. O. Rabin, and E. Shamir: The Theory of Definite Automata, IEEE Trans. Electron. Computers, June, 1963, pp. 233-243.
Huffman, D. A.: Canonical Forms for Information Lossless Finite-state Machines, IRE Trans. Circuits Theory, vol. CT-6, Special Supplement, pp. 41-59, May, 1959.
9. Zvi Kohavi, Switching and Finite Automata Theory, 1976
[1]
В 2000 г. сотрудники RSA Laboratories предложили всем желающим взломать 140-разрядный ключ шифрования RSA. В течение месяца ключ был взломан. Тогда RSA Laboratories бросила криптографической общественности новый вызов, предложив проверить на прочность 512-разрядный ключ. На этот раз «крепость» RSA держалась чуть больше семи месяцев. После этих экспериментов специалисты RSA Laboratories рекомендуют использовать ключи шифрования длиной не менее 768 бит. Растет вычислительная мощность процессоров, а параллельно совершенствуются средства, позволяющие быстро взламывать криптографические системы.
Паула Шерик – редактор Windows 2000 Magazine и консультант по вопросам планирования, реализации и взаимодействия сетей.
[2] Эта проблема существует во всех криптографических алгоритмах. Особенно остро она возникает в RSA, где надежность зависит от размерности применяемых простых чисел, для которых до сих пор не существует алгоритм эффективной генерации.
[3]
Под правилом
здесь понимается совокупность признаков, по которым, не выполняя преобразования, можно однозначно определить наличие или отсутствие определенного качества. Например, правило проверки числа на четность и тому подобное.
[4] См. Cryptography.Ru, http://www.cryptography.ru/db/msg.html?mid=1169833
[5] Далее мы будем применять термины «машина» и «конечный автомат», как синонимы.
[6]
Первоначально, предполагаем, что М находится в любом своем состоянии.
[7] Следует обратить внимание, что эти умозрительные эксперименты производятся с известной
таблицей переходов.
[8] Для криптографии эти условия просто не приемлемы, так как информация о машине Мi и µ
является секретной для всех, кроме «хозяина» закодированной информации.(Моё прим.)
[9]
Эта процедура довольно запутана. В предлагаемой работе предлагается алгоритмическое решение. Оно заключается в том, что инверсная машина должна иметь начальное состояние, из которого есть выход, но нет в него перехода.
[10]
Применение этой модели для кодирования и декодирования имеет смысл если исходное состояние машины М открыто, а состояние *М секретно, то есть, известно только декодирующему. В этом случае декодирование не всегда может быть выполнено правильною.
[11] В строках (D,1,0) и (D,1,1) (см. столбец PS) переходы совпадают с переходами в строках S1 и S2 соответственно, это значит, что эти состояния эквивалентны.
[12]
Алгоритм построения инверсного автомата рассмотрен в разделе «Минимальная инверсная машина». (см. стр. 18)
[13]
Процесс тестирования описан в разд. «Тестирующая таблица и тестирующий граф». Более того, если бы А1 не был КАМСИ, то для него невозможно построить инвертор.
[14]
Имеется ввиду, что обе таблицы переходов имеют по 2 состояния.
[15]
Не трудно показать, что при изменении обозначения состояний в таблице переходов, алгоритм не изменяется.
[16] В этом случае под декомпозицией мы понимаем операцию, обратную композиции. В результате декомпозиции исходный автомат разбивается на несколько компонентов.
[17] Термин «примитив» в этом контексте предполагает, что он является КАМСИ и входит составной частью в КАМСИ-композицию.
[18] Хотя число состояний кодера и декодера могут быть разными, они имеют одинаковый ?-порядок. Поэтому сложность их инвертирования имеет одинаковый порядок ?22?.
[19] ?-порядок может быть определен при экспериментировании с ?(m).
[20]
Ниже будет показано, что в Библиотеке Примитивов содержатся разные примитивы с одинаковыми параметрами.
[21]
Количество примитивов должно быть таким, чтобы существовала возможность выбора из достаточно большого числа вариантов.
[22]
Понятие кортежа будет дано в следующем разделе.
[23]
Допустимо применять одинаковые примитивы в разных позициях.
[24]
Базовой может быть любая КАМСИ-компонента.
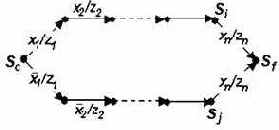
Свойства последовательного соединения КАМСИ
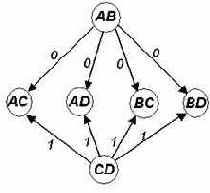
Рассмотрим последовательное соединение двух КАМСИ А1 и А2 (см. Рис. 8, стр. 26).
До сих пор мы рассматривали последовательное соединение двух КАМСИ, кодера и декодера, которые соединены информационным каналом, и поэтому их нельзя заменить одним автоматом.
Теперь мы рассмотрим такое объединение конечных автоматов, которое интересует нас постольку, поскольку его можно заменить эквивалентным конечным автоматом.
Рассмотрим способ построения такого автомата, его свойства и параметры.
Рис. 8
Докажем следующее утверждение.
Утверждение 5. Композиция двух последовательно соединенных КАМСИ А1=>А2 (Рис. 8) является КАМСИ, которая имеет порядок ?(A1+A2)=?(A1)+?(A2), где ?(A1) и ?(A2) - ?-порядки КАМСИ А1 и А2, соответственно
Доказательство.
Из определения КАМСИ следует, что ?(A1) символов входного потока битов (Р), поданных на вход КАМСИ А1 достаточно, чтобы определить первый символ Р на выходе Е1. Однако, на выходе Е2 он может появиться только через ?(A2) битов
Е1 на входе КАМСИ
А2. Отсюда следует, что первый символ Р на выходе Е2 может быть получен после ?(A1+A2)=?(A1)+?(A2) символов, поданных на вход Р, то есть, композиция КАМСИ А1,А2
также является КАМСИ и имеет порядок ?=?(A1)+?(A2).
Пример 1
В Table 13(a) и (b) приведены таблицы переходов КАМСИ А1 и А2
µ-порядка 2, а в Table 13(c) и (d) – инверсные им автоматы SS1
и SS2, соответственно ([12]).
А1
P,E
P=0
P=1
A
B,0
A,0
B
A,1
B,1
(a)
А2
P,E
P=0
P=1
A
A,1
B,1
B
B,0
A,0
(b)
?(A1)=2
?(A2)=2
SS1
P,E
E=0
E=1
S0
S1,1
S2,1
S1
S1,1
S2,1
S2
S3,0
S4,0
S3
S1,0
S2,0
S4
S3,1
S4,1
(c)
SS2
P,E
E=0
E=1
S0
S1,0
S2,0
S1
S1,0
S2,0
S2
S3,1
S4,1
S3
S1,1
S2,1
S4
S3,0
S4,0
(d)
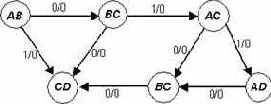
Table 13
Обозначим через А1 и SS1 кодер и декодер, соответственно, (аналогично А2 и SS2). В Table 14 и в Table 15 (строка (а)) приведен один и тот же поток бит Р (кодируемый текст, который известен только отправителю, см. Table 14(а)). В строках (b) таблиц приведены состояния, в которые переходят автоматы А1 и А2, соответственно. В строках (с) – значения на выходе – закодированный текст, который может быть известен всем (например, передаваться по незащищенному каналу). В строках (d) и (e) приведены результаты декодирования, которые показывают, что результаты декодирования совпадают с исходным текстом, но появляются, начиная с третьего бита, то есть, с задержкой, равной двум.
Table 16
P
1
1
0
1
0
0
1
1
0
0
1
0
0
1
1
1
A1
A
A
A
B
B
A
B
B
B
A
B
B
A
B
B
B
B
E1
0
0
0
1
1
0
1
1
1
0
1
1
0
1
1
1
A2
A
A
A
A
B
A
A
B
A
B
B
A
B
B
A
B
A
E2
1
1
1
1
0
1
1
0
1
0
0
1
0
0
1
0
SS1
S0
S2
S4
S4
S4
S3
S2
S4
S3
S2
S3
S1
S2
S3
S1
S2
S3
E`
1
0
1
1
1
0
0
1
0
0
0
1
0
0
1
0
SS2
S0
S2
S3
S2
S4
S3
S1
S1
S2
S3
S1
S1
S2
S3
S1
S2
S3
P`
0
1
1
1
0
1
0
0
1
1
0
0
1
1
0
1
Table 17
На основании «Утверждение 5» (см. стр. 26) и «Утверждение 6» (см. стр. 30) можно сделать вывод: если последовательность автоматов состоит из m КАМСИ-компонентов, то они представляют собой КАМСИ-композицию µ-порядка, равного
Форм. 2.
Тест для внешней (выходной) памяти
Основной инструмент для определения, имеет ли данная машина конечную выходную память – это модифицированная тестирующая таблица и ее тестирующий граф. Тестирующая таблица (для выходной памяти), состоит из двух частей, имеет q
столбцов O1O2…Oq, соответствующих различным значениям выходов. Строки верхней части имеют имена состояний таблицы переходов М. На пересечении Si
строки и Оj
столбца записывается состояние, в которое будет переход из Si
при значении Оj
на выходе. Будем называть эти состояния Оj-премниками Si. Клетки верхней половины таблицы заполняются соответствующими преемниками. Верхняя часть таблицы называется таблицей выходных преемников (наследников). Таким образом, машина М Table 3а имеет
PS
NS,z
x=0
x=1
A
B,0
D,1
B
C,1
A,1
C
B.0
C,0
D
C,0
C,1
PS
z=0
z=1
A
B
D
B
-
(AC)
C
(BC)
-
D
C
C
AB
-
(AD)(CD)
AC
(BB)(BC)
-
AD
(BC)
(CD)
BC
-
-
BD
-
(AC)(CC)
CD
(BC)(CC)
-
a)
b)
c)
Table 3
выходные 1-преемники состояния В состояния А и С и не имеет ни одного 0-преемника. В Table 3b это соответствует заполнению строки В верхней половины таблицы. Для каждой пары состояний в нижней части таблицы записываются соответствующие преемники. Выходной Ок-преемники SiSj – парные сочетания выходных Ок-преемники из Si и Sj. Например, если преемниками из Si и Sj есть SpSq и SrSt, соответственно, тогда их преемники имеют вид: SpSr, SpSt, SqSr
и SqSt.
Тестирующий (для выходной памяти) граф такой, что:
поставить в соответствие каждой строке нижней половины таблицы вершину графа и присвоить им имена этих строк.
соединить дугами вершины, которые в таблице являются в отношении источник-преемник.
Пример тестирующего графа приведен в Table 3с. Обратите внимание, что из вершины АВ выходит две дуги с одинаковыми значениями выхода, равного 1.
Утверждение 2 Машина М имеет конечную выходную память, если и только если тестирующий граф не имеет циклов. Если граф, свободный от циклов, имеет наибольший путь длинной l, то М имеет выходную память порядка µ= l+1.
В примере Table 3с граф свободен от цикла и наибольший путь AB=>AD=>CD=>BC равен 3, а порядок µ=4.
Обратите внимание, что граф не содержит вершин с повторяющимися вхождениями, например, ВВ
и т.д.. Наличие таких пар не влияет на неопределенность.
Тест на информацию сохраняемость
Перейдем к получению теста, позволяющего определить, является ли данная машина информацию сохраняющей и каков ее ?-порядок, если она конечна. Прежде, чем перейти к тестирующей процедуре, введем некоторые термины.
Определение. 6 Два состояния Si
и Sj будем называть сочетаемыми по выходу, если существует некоторое состояние Sp
такое, что оба Si и Sj являются его Ок-преемниками или если существует сочетаемая пара SrSt
такая, что SiSj
имеют свои Ок-преемники. В таком случае будем говорить, что из сочетаемости (SiSj) вытекает сочетаемость (SrSt).
Первый шаг тестирующей процедуры есть проверка каждой строки таблицы для выявления двух идентичных переходов имеющих одинаковые значения выходов. Если нет идентичных вхождений, следующий шаг – это построение таблицы переходов по выходам.
Тестирующая таблица (информацию сохраняющая) состоит из двух частей. Верхняя часть содержит выходные
PS
NS,z
x=0
x=1
A
A,1
C,1
B
E,0
B,1
C
D,0
A,0
D
C,0
B,0
E
B,1
A,0
PS
z=0
z=1
A
-
(AC)
B
E
B
C
(AD)
-
D
(BC)
-
E
A
B
AC
-
-
AD
-
-
BC
(AE)(DE)
-
AE
-
(AB)(BC)
DE
(AB)(AC)
-
AB
(AB)(BC)
a)
b)
c)
Рис. 5
преемники, а нижняя половина строится следующим образом: в каждой строке записывается сочетание из верхней таблицы (AC,AD и BC). Преемники в этой таблице строятся обычным способом, и состоят из сочетаемых пар. Если при этом появляется очередная сочетаемая пара (например, АЕ и DЕ в строке ВС), которую записывают в новую строку, и т.д..
На Рис. 5а приведен пример Машины, на котором рассмотрим описанную процедуру.
Таблица выходных переходов показана в верхней части таблицы Рис. 5b. (AC) является сочетаемой парой (А и С имеют одинаковые значения выходов), по этой причине эта пара записывается в нижнюю часть таблицы. Остальные строки заполняются аналогично.
Сформулируем необходимые и достаточные условия существования информацию сохраняющей машины.
Утверждение 3 Машина является информацию сохраняющей, если и только если тестирующая таблица не содержит сочетаемые пары с повторяющимися компонентами.
Тестирующий граф (для информационной сохраняемости) есть направленный граф, в котором:
каждая вершина графа соответствует совместимой паре таблицы.,
дуга, обозначенная Ок
направляется из вершины SiSj
в вершину SpSq
(где p?q), если и только если (SpSq) находится в строке SiSj.
Пример тестирующего графа приведен на Рис. 5с. Как видно из графа, машина является информацию сохраняющей.
Прежде, чем определить ?-порядок, рассмотрим утверждение:
Утверждение 4. Машина есть информацию сохраняющая порядка µ=l+2, если тестирующий граф свободен от циклов и длина наибольшего пути графа равна l.
Доказательство.
Допустим, что машина М – информацию сохраняющая. Примем, что граф не имеет цикла. Очевидно, что каждая совместимая пара достижима из некоторого состояния М при паре соответствующих входных последовательностей, которые выдают идентичные выходные последовательности. Поэтому мы можем найти пару различных входных последовательностей, которые переводят М в состоянии SiSj, при выработке идентичных выходных последовательностей. Если мы теперь осмотрим выходные символы, которые производит машина, до тех пор, пока не пройдем все сочетаемые пары в цикле, то мы обнаружим, что М возвратится в состояние SiSj
без любой дополнительной информации, чтобы получить первый входной символ. И так как этот цикл может повторяться много раз, при желании, мы можем создать пару произвольно длинных входных последовательностей, которые начинаются в некотором состоянии М и отличаются первыми символами, но вырабатывают одинаковые выходные последовательности. Таким образом, М не является информацию сохраняющей конечного порядка
Из «Утверждение 4» следует, что если М – информацию сохраняющая машина порядка µ, то µ?1+n(n-1)/2.
При µ=1 отсутствуют сопоставимые пары (см. Table 5), в то время, как при µ=2 обнаруживает отсутствие дуг. Если вернуться к графу на Рис. 5с то мы увидим, что он имеет цикл, поэтому машина не информацию сохраняющая конечного порядка.
Пример.
Еще один пример построения теста показан на Рис. 6. Как видно из Рис. 6с, тестирующий граф не имеет цикла и, так как l=1, то µ=3.
NS,z
PS
z=1
z=0
B,0
A,0
A
D,0
C,0
B
C,1
D,1
C
A,1
B,1
D
PS
z=0
z=1
A
(AB)
-
B
(CD)
-
C
-
(CD)
D
-
(AB)
AB
(AC)(AD)
(BC)(BD)
-
CD
-
(AC)(AD)
(BC)(BD)
a)
b)
c)
Рис. 6
Тестирующая таблица и тестирующий граф
Примем, что существует машина М1, заданная Table 1а.. Мы можем переписать эту таблицу, как показано в верхней половине таблицы Table 1b. В заголовке этой таблицы записаны все сочетания значений входов-выходов. Остальные строки верхней половины таблицы заполняются состояниями, в которые произойдет переход при соответствующем значении входа-выхода. Например, 1-суксессор (наследник) состояния С есть В и соответствующее значение выхода равно 1. Поэтому В вписан в строке С в столбец 1/1 и вписана черточка в столбце 1/0.
В первом столбце нижней части таблицы выписаны все паро-сочетания состояний, которые образованы из состояний верхней части таблицы. Если в строках Si
и Sj в столбце Ik/Ol
в верхней части таблицы есть Sp и Sq,
соответственно, тогда в строке SiSj в нижней части таблицы в столбце Ik/Ol записываем SpSq. Если для некоторой пары состояний Si
и Sj в столбце Ik/Ol
в верхней части таблицы присутствует хотя бы одна черточка, то в строке SiSj
в столбце Ik/Ol следует поставить черточку.
PS
NS,z
x=0
x=1
A
B,0
C,1
B
D,0
C,0
C
D,0
B,1
D
C,0
A,0
a)
0/0
0/1
1/1
1/0
A
B
-
C
-
B
D
-
-
C
C
D
-
B
-
D
C
-
-
A
AB
BD
-
-
-
AC
BD
-
BC
-
AD
BC
-
-
-
BC
DD
-
-
-
BD
CD
-
-
AC
CD
CD
-
-
-
b)
Table 1
Таблица вида Table 1 называется тестирующей таблицей.
Мы будем называть пару SiSj, как неопределенную пару, и ее преемника SpSq, как предполагаемую пару. Например, пара АС порождает пару BD.
Определим теперь направленный граф G, который будем называть тестирующий граф, который построен следующим способом.
Рис. 1
Поставить в соответствие каждой строке нижней половины тестирующей таблицы вершину графа.
Соединить стрелкой вершину SiSj
с вершиной SpSq, где p ? q, если и только если существует SpSq
в строке SiSj
и столбце Ik/Ol
тестирующей таблицы. Стрелку обозначить Ik/Ol.
Тестирующий граф G1 машины M1 (см. Table 1b) показан на Рис. 1
Условия сохраняемости (lossiness) информации
Машина, которая не сохраняет информацию называется не сохраняющей (lossy) информацию.
Простой пример не сохраняющей машины – это такая, в которой для некоторого состояния Si
и двух отличных входных символов Ip и Iq, Ip- и Iq-преемники и соответствующие им выходы идентичны. Ясно, что в таком случае знание выхода, начального и конечного состояния не достаточно, чтобы определить, какой из Ip ,Iq были поданы на вход машины.
Рис. 3
Потеря информации происходит тогда, когда существуют два состояния Si и Sj, которые могут быть достигнуты от одного и того же состояния Sс, которые могут быть достигнуты при различных входных последовательностях, которые переводят машину в одно и то же состояние Sf
и генерируют одинаковые выходные последовательности (см. Рис. 3).
Пример. Пусть задана машина, таблица переходов которой показана на Рис. 4а. Как видно из Рис. 4b, эта машина относится к типу несохранающих информацию. В этом случае две различные входные последовательности (01 и 10) переводят машину из состояния А в В и производят одинаковую выходную последовательность.
Приведенное выше показывает, что прежде, чем планировать тестирующий эксперимент, необходимо проверить, является ли она информацию-сохраняющей. Необходимо определить, для некоторого состояния, не возникает ли ситуация, показанная на Рис. 3. Прежде чем рассматривать построение теста на информационную сохранность, определим порядок информационной сохранности.
PS
NS,z
x=0
x=1
A
A,0
B,0
B
B,0
A,1
a)
b)
Рис. 4
Условия существования конечной памяти.
Допустим, первоначальная неопределенность относительно состояния машины М (S1
S2…Sn) ([6]).
Определение. 3 М есть конечная память µ-порядка если подача любой входной последовательности длиной µ переводит машину в распознаваемое состояние, и если существует входная последовательность длиной µ-1, которая, вместе с соответствующей выходной последовательностью не содержит информацию, необходимую для точного определения конечного состояния.
Утверждение 1. Последовательная машина М имеет конечную память, если и только если ее тестирующий граф не имеет циклов.
Доказательство. Допустим, G имеет цикл. Тогда, при повторении подачи символов, соответствующих метке перехода цикла, мы получим входную последовательность произвольной длины, которая не позволит определить конечное состояние, то есть машина не обладает конечной памятью. Чтобы доказать достаточность, примем, что G не имеет циклов. Если М не обладает конечной памятью, то существует произвольно длинный путь в G, соответствующий некоторой входной последовательностью Х и некоторая пара состояний SiSj
такая, что Si и Sj
не могут быть отличены при Х. Но так как число вершин в G не может превосходить (n-1)n/2
(соответствующее числу отличных пар состояний) произвольно длинный путь в G возможен только если он содержит цикл. Утверждение 1 доказано.
Пример. Из тестирующего графа M1
(Рис. 1) видно, что G1 имеет два цикла. Следовательно, M1 не обладает конечной памятью.
Следствие.
Допустим, G свободный от циклов тестирующий граф для машины М. Если длина наибольшего пути равна l, то µ=
l+1.
Доказательство. Так как G свободен от циклов, то М обладает конечной памятью. Допустим, что µ> l+1; тогда существует минимум одна неопределенная пара SiSj,
которая будет переведена при подаче входной последовательности длиной l+1 в другую пару SpSq. Следовательно, существует путь вежду вершинами SiSj
и SpSq
длиной l+1. Но это противоречит нашему допущению и, следовательно, µ не может превышать l+1.
На основании приведенного выше вытекает, что µ?(n-1)n/2.
Причина низкой производительности существующих асимметричных
Причина низкой производительности существующих асимметричных алгоритмов заключается в том, что применяемые на практике асимметричные алгоритмы используют, так называемую, «длинную» арифметику, то есть арифметику, предназначенную для работы с числами размером от сотни и более цифр. Вследствие этого быстродействие асимметричных алгоритмов на несколько порядков меньше симметричных алгоритмов.
Надежды на то, что с ростом быстродействия технических средств разрыв между быстродействием асимметричных и симметричных алгоритмов будет сокращаться, безосновательны. Следует понять, что с ростом быстродействия технических средств, при сохранении размера чисел, снижается степень защищенности алгоритма, а это, в свою очередь, приводит к необходимости увеличить размерность «арифметики» ([1]).
Возникло целое направление в криптографии, так называемые теоретико-числовые алгоритмы (например, RSA), которое за последние двадцать лет привело к появлению большого числа оригинальных асимметричных алгоритмов и это создало иллюзию, что термины «асимметричный алгоритм» и «длинная арифметика» - синонимы.
Так ли это?
Для доказательства ошибочности этих представлений, далее будет рассмотрен асимметричный алгоритм кодирования на базе конечно-автоматной модели.
Будет показано, что, если трудность взлома RSA связана со сложностью выполнения операции разложения числа на простые сомножители (это и приводит к необходимости использования «длинной арифметики»), то для конечно-автоматной модели аналогичной операцией является декомпозиция кодера на простые компоненты.
Далее будет показано, что сложность декомпозиции конечного автомата возрастает экспоненциально, в то время, как его быстродействие не зависит от размера его таблицы переходов.
По аналогии с понятиями сложного и простого числа в теории чисел, далее будут введены понятия композиции конечных автоматов и примитивов. Особенность заключается в том, что если сложное число в теории чисел всегда может быть разложено на простые числа, для которых отсутствует понятие порядка их взаимного расположения в произведении (коммутативность перестановок сомножителей в произведении), то для конечного автомата, эквивалентного композиции примитивов, имеют значение, как их набор, так и порядок их взаимного расположения в композиции. Другими словами, композиция автоматов из примитивов не обладает свойством коммутативности.
КАМСИ (Конечно- Автоматная Модель, Сохраняющая Информацию) были достаточно полно исследованы более сорока лет назад, и, все-таки, они не нашли до сих пор применения в криптографии. Почему же это - так, несмотря на то, что существующие, так называемые, паблик-кей технологии (технологии с открытым ключом) по производительности и сложности реализации оставляют желать лучшего?
Этому может быть несколько причин.
Описанный в литературе способ применения КАМСИ представляет собой однонаправленную функцию без секрета.
Действительно, асимметричность здесь объясняется тем, что алгоритмы кодирования отличаются от алгоритмов декодирования. Однако, сложность построения инвертора (декодера) экспоненциально зависит от µ (одного из параметров КАМСИ, о котором будет сказано ниже) и эта сложность одинакова для всех участников процесса обмена информацией (как для отправителя, так и для всех участников информационного процесса).
Можно высказать различные предположения о том, почему эта проблема не была разрешена до сих пор. Но, учитывая высокий уровень ученых – специалистов в области Теории Конечных Автоматов, которые разрабатывали теорию КАМСИ (см. список литературы на стр. 46), можно привести одно - Теория Конечных Автоматов изначально создавалась только
для анализа и реализации алгоритмов управления технологическими процессами, которые разрабатывались другими и в других областях науки. В криптографии же возникает проблема генерации криптографических алгоритмов, которые должны обладать определенными свойствами.
Каковы же перспективы применения КАМСИ в криптографии?
Очень заманчиво, но бесполезно для применения в криптографии, попытаться усовершенствовать алгоритм инвертирования КАМСИ. Разумеется, что как любое усовершенствование, оно интересно.
Однако, любое усовершенствование «облегчает жизнь» всем участникам процесса обмена информацией, в том числе, и недобросовестным. Так, рассмотренные Цви Кохави (см. Список литературы, стр. 46) описываются последовательные линейные Машины, которые называются линейными потому, что сложность их преобразования линейно зависит от размера Машины, однако, это «облегчает жизнь» всем
участникам процесса обмена информацией. То есть, оно не может привести к созданию «секрета» однонаправленной функции. Более того, трудно рассчитывать, что любые усовершенствования удастся длительно держать в секрете, тем более, что понятие «недобросовестный пользователь» среди участников информационного процесса может изменяться в зависимости от характера защищаемой информации.
Из этого следует, что сама по себе разработка теории КАМСИ не может привести к созданию однонаправленной функции с секретом.
Есть и еще одно обстоятельство, которое создавало проблему применения КАМСИ в криптографии: это - необходимость автоматизации процесса генерации кодера ([2]).
Хотя для симметричного алгоритма этот процесс решен достаточно успешно, но при этом возникает проблема «защищенной» доставки нового сгенерированного ключа участнику процесса обмена информацией. В асимметричном алгоритме проблема «защищенной» доставки отсутствует, так как открытый ключ нет необходимости охранять, а секретный – некому посылать. В этом случае «секретность» держится на «трудности» получения закрытого ключа из открытого.
Например, в RSA, для «взломщиков» существует проблема разложения сложного числа (открытый ключ) большой размерности (сто цифр и больше) на простые сомножители (секретный ключ). Это держится на том, что не существует рациональный способ автоматической генерации простых чисел большого размера. К сожалению (для науки) и к счастью (для создателей алгоритма), до сих пор процесс тестирования большого числа на «простоту» требует огромных затрат времени и технических ресурсов (в этом и заключается «секрет» однонаправленной функции для RSA).
Это одна из причин, по которой существующие асимметричные алгоритмы сложны для внедрения.
Коротко сложившуюся ситуацию можно назвать проблемой отсутствия правила.([3])
Для RSA – это отсутствие правила проверки «на простоту». На практике это приводит к тому, что часто используют псевдопростые числа.
Для КАМСИ в опубликованных исследованиях так же отсутствует простое правило
проверки на «КАМСИ-шность».
Это главная причина, по которой КАМСИ до сих пор не получила применения в криптографии.
В предлагаемой работе проблема «правила» для КАМСИ решена неожиданным образом: предложена ситуация, в которой нет необходимости
проверки на «КАМСИ-шность». Это стало возможным потому, что разработаны операции преобразования КАМСИ, сохраняющие свойство КАМСИ (в отличие от простых чисел, о которых известно, что любые преобразования простых чисел дают сложные числа, но не наоборот).
В предлагаемой работе введены понятия КАМСИ-примитива
и КАМСИ-композиции, которые можно считать аналогами простого и сложного числа в теории чисел.
В предлагаемом алгоритме, «секретом» является разложение КАМСИ-композиции на примитивы.
Особенность «секрета» однонаправленной функции на базе КАМСИ, в отличие от RSA, является то, что, если для сложного числа существует, в виде секретного ключа, набор
простых чисел – сомножителей, для которых безразличен порядок их использования для получения произведения (коммутативность), то для каждой КАМСИ-композиции, кроме набора
примитивов, существенным является порядок
расположения их в композиции.
В работе «Асимметричный криптографический алгоритм на базе Конечно-Автоматной Модели, Сохраняющей Информацию (КАМСИ)» ([4]) мы рассмотрели свойства КАМСИ и возможности реализации на их основе различных криптографических протоколов.
В предлагаемой работе мы рассмотрим основные свойства КАМСИ, которые позволят применить их для реализации асимметричных криптографических алгоритмов.
Для этого мы рассмотрим следующие вопросы:
Основные свойства КАМСИ.
КАМСИ-примитивы.
Реализация однонаправленной функции на базе КАМСИ.
Начнем с определения понятия однонаправленной функции.