Признаков OLAP Данных
Многомерная концепция данных.
OLAP оперирует данными CUBE (см. далее описание работ Грея [8]), которые являются многомерными массивами. Число измерений OLAP-кубов не ограничено.
Прозрачность.
OLAP системы должны опираться на открытые системы, поддерживающие гетерогенные источники данных.
Доступность.
OLAP системы должны представлять пользователю единую логическую схему данных.
Постоянная скорость выполнения запросов.
Производительность не должна падать при росте числа измерений.
Клиент/сервер архитектура.
Системы должны базироваться на открытых интерфейсах и иметь модульную структуру.
Различное число измерений.
Системы не должны ограничиваться трехмерной моделью представления данных. Измерения должны быть эквивалентны по применению любых функций.
Динамическое представление разреженных матриц.
Под разреженной матрицей понимается такая матрица, не каждая ячейка которой содержит данные. OLAP-системы должны содержать средства хранении и обработки разреженных матриц больших объемов.
Многопользовательская поддержка.
OLAP-системы должны поддерживать многопользовательский режим работы.
Неограниченные многомерные операции.
Аналогично требованию о различном числе измерений: все измерения считаются равными, и многомерные операции не должны накладывать ограничения на отношения между ячейками.
Интуитивно понятные инструменты манипулирования данными.
Для формулировки многомерных запросов пользователи не должны работать со усложненными меню.
Гибкая настройка конечных отчетов.
Пользователи должны иметь возможность видеть только то, что им необходимо, причем все изменения данных должны немедленно отображаться в отчетах.
Отсутствие ограничений.
Не должны иметься какие-либо ограничения на количество измерений и уровней агрегации данных.
Агрегирующие функции, меры и формулы
Неотъемлемой частью OLAP-модели является задание функций агрегирования. Поскольку целью OLAP является создание многоуровневой модели анализа, данные на уровнях, отличных от фактического, должны быть соответствующим образом агрегированы. Важно отметить, что по каждому измерению можно задавать собственную (и не одну) функцию агрегации. Таким образом, в случае куба с

измерениями функция агрегирования:

где

— точка куба, а

-

-ая функция агрегирования по

-ому измерению.
В [7] приведена следующая классификация агрегирующих функций с точки зрения сложности распараллеливания.
Категории агрегирующих функций
Дистрибутивные функции
позволяют разбивать входные данные и вычислять отдельные итоги, которые потом можно объединять.
Алгебраические функции
можно представить комбинацией из дистрибутивных функций (например, Average() можно представить как

Холистические функции
невозможно вычислять на частичных данных или представлять каким-либо образом.
Эта классификация окажется полезной, когда мы будем рассматривать классы разбиения в алгоритме Quotient Cube (см. раздел , работы [12],[11],[26]), в котором разбиение по покрытию применимо для дистрибутивных и алгебраических функций.
Вперед: Виды запросов к кубам
Выше: Введение. Анализ задачи
Назад: История Задачи
Алгоритм Bottom-Up Computation
BUC-алгоритм предназначен для вычисления разреженных кубов и кубов типа айсберг. При этом, в отличие от MultiWay, куб рассчитывается от наиболее общего подкуба к детальным подкубам. Поэтому можно снизить затраты на партиционирование данных. К тому же подобный порядок позволяет наиболее эффективно использовать условие Apriori, снижая объем необходимых вычислений.
Bottom-Up Computation переводится как вычисление "снизу вверх", что вызывает недоумение, т.к. структуры кубов принято изображать, располагая детальные подкубы ниже, а агрегирующие выше. С этим связаны и термины roll-up и drill-down: мы или поднимаемся выше по структуре, агрегируя данные (roll-up), либо спускаемся к детальным элементам (drill-down). Однако авторы работы [4], использовали противоположный подход, и название алгоритма закрепилось.
На рисунке изображена схема работы алогоритма BUC для создания трехмерного куба ABC, с измерениями A, B и С.
В общих чертах, алгоритм работает следующим образом:
Агрегируется весь набор входных данных и записывается итоговый результат.
Для каждого измерения d входные данные партиционируются по d, т.е. для каждого уникального элемента d создается партиция.
Для каждой партиции, созданной на предыдущем шаге, проверяется условие MinSup. К примеру, если задано условие count > x, то проверяется количество кортежей в партиции.
Если партиция удовлетворяет условию MinSup, то рекурсивно запускается алгоритм BUC, и в качестве входных данных используется эта партиция. Таким образом вычисляется куб типа айсберг по измерениям, начиная от d+1.
После возвращения из вложенных рекурсивных вызовов на партициях по измерению d, алгоритм повторяется для следующего измерения.
Рассмотрим работу алгоритма на примере создания четырехмерного куба с измерениями A, B, C и D и условием MinSup "count > 3". Предположим, что измерение А содержит 4 элемента

, измерение B - 4 элемента

, измерение C - 2 элемента

и измерение D - 2 элемента

. Поскольку каждый подкуб является партцией, то в соответствии с условием MinSup нам необходимо вычислить все подкубы, агрегирующие более трех кортежей.
Рисунок показывает порядок партиционирования исходных данных по различным элементам измерения А, затем В, С и D. Для этого BUC сканирует исходные данные, агрегируя все кортежи, чтобы получить итоговое значение all. Партиционирование по измерению А создает 4 партиции, при этом запоминается количество кортежей в каждой партиции.
 |

измерения A, кортежи партиции
агрегируются с вычислением значения
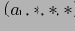
. Предположим, что
удовлетворяет условию MinSup, тогда запускается рекурсивное вычисление для партиции
.
партиционируется по измерению В. Проверяется количество кортежей для

. Если для
условие MinSup удовлетворяется, то партиционирование продолжается по C, начиная с

. Если же в
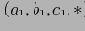
количество исходных фактов равно 2, что не удовлетворяет исходному условию MinSup , то по лемме Apriori и ни один из потомков не будет удовлетворять условию MinSup. В этом случае алгоритм BUC не вычисляет дальше
, избегая затрат на партиционирование по измерению D. Вычисляется

и так далее.
Производительность алгоритма BUC зависит от порядка измерений и симметричности данных. Измерения должны обрабатываться в порядке убывания мощности (количества элементов). Чем больше мощность измерения, тем меньше партиции и больше вариантов для применения условия MinSup. Аналогично, равномерные измерения (когда данные равномерно распределены по элементам) лучше подходят для применения условия Apriori.
Основным достоинством алгоритма BUC можно считать эффективное распределение затрат на партиционирование. Однако, в отличие от MultiWay, расходы на агрегирование не разделяются между родителями и потомками. К примеру, результаты вычисления подкуба AB не используются для вычисления подкуба ABC, который нужно вычислять с нуля.
Вперед: Алгоритм Star-Cubing
Выше: Вычисление Iceberg кубов
Назад: Вычисление Iceberg кубов
Алгоритм DWARF
Алгоритм DWARF (карлик) (см. [21]) назван так с намеком на звезды карликового типа, которые имеют небольшой объем, но огромную массу. Это синтаксический алгоритм, распознающий два типа избыточности хранения данных и устраняющий их во время создания и поддержки куба.
Ключевыми понятиями алгоритма являются префиксная избыточность и суффиксная избыточность (см. ).
В пользу практического использования алгоритма DWARF говорит автоматическое нахождение префиксных и суффиксных избыточностей, не требующее каких-либо знаний о распределении данных, типов, значений. При этом эффективность сжатия одинаково высока как и для ''разреженных'', так и для ''плотных'' кубов. В большинстве случаев даже для очень плотных кубов размер результирующего DWARF куба меньше размера базовой таблицы. Если для ''плотных'' кубов улучшения происходят за счет префиксной избыточности, то, по мере того как кубы становятся ''разреженнее'', возрастает доля суффиксной избыточности.
Не менее важным является сокращение времени создания и расчетов. Каждый избыточный суффикс идентифицируется до его вычисления, что ведет к существенным уменьшениям времени создания. Более того, вследствие уменьшения общего размера куба пропорционально падает и время обработки запросов.
Алгоритм Star-Cubing
Алгоритм Star-Cubing, представленный в работе [13], предназначен для вычисления кубов типа айсберг. В алгоритме сочетаются агрегирование "снизу-вверх" и "сверху-вниз", многопозиционное агрегирование (как в ) и применение леммы Apriori (как в ). Данные хранятся в специальной структуре star-tree, эффективно сжимающей данные, что позволяет сократить время расчета и объем потребляемых ресурсов.
На уровня подкубов используется агрегирование снизу-вверх, однако существует уровень обнаружения разделяемых измерений, в котором работа идет сверху-вниз. Подобное сочетание позволяет алгоритму агрегировать по нескольким измерением одновременно, разделяя затраты на агрегирование и используя для отсечения подкубов, не удовлетворяющих условию MinSup .
Последовательность вычислений в алгоритме Star-Cubing проиллюстрирована на рисунке , описывающем вычисление четырехмерного куба ABCD. Если бы использовалась только вычисление снизу-вверх, то подкубы, помеченные словом "отсечено", были бы вычислены. Star-Cubing может отсечь указанные подкубы, принимая в расчет разделяемые измерения. Здесь ACD/A означает, что подкуб ACD имеет разделяемое измерение А, ABD/AB — подкуб AB имеет разделяемое измерение AB, ABC/ABC — подкуб ABC имеет разделяемое измерение ABC и т.д. Таким образом, все подкубы ветви, начинающейся с ACD, включают измерение A, ветви, начинающейся с ABD,- измерение AB, ветви, начинающейся с ABC,- измерение ABC. Подобные измерения называются разделяемыми для соответствующих ветвей.
Схема работы алгоритма Star-Cubing, обработка подкубов снизу-вверх и использование разделяемых измерений
Поскольку разделяемые измерения можно обнаружить в самом начале вычисления дерева подкубов, можно избежать перевычисления подобных измерений в дальнейшем. К примеру, подкуб AB, вычисляемый из ABD, отсечен, т.к. уже вычислен в ABD/AD. Аналогично отсекается куб A, вычислимый из AD, т.к. уже вычислен ACD/A.
Напомним, что необходимым условием использования является дистрибутивность используемой агрегирующей функции.
К примеру, если в разделяемом измерении А значение
не удовлетворяет условию MinSup, то отсекается вся ветвь от

(включая

), поскольку эти ячейки заведомо не удовлетворяют условию MinSup.
Прежде чем приступить к примеру работы алгоритма, введем несколько понятий.
В алгоритме для представления индивидуальных подкубов используются деревья. На рисунке
изображена часть дерева куба для подкуба ABCD. Каждый уровень дерева представляет собой измерение, и каждый узел представляет собой значение атрибута. Каждый узел имеет 4 поля: значение аттрибута, агрегированное значение, указатель/указатели на потомков и указатель/указатели на элементы того же уровня. Кортежи подкуба вставляются в дерево один за другим. Путь от корня к листу представляет собой кортеж. К примеру, агрегированное значение (по мере count) узла

в дереве равно 5, что означает 5 ячеек значения
. Подобное представление позволяет сократить пространство, требуемое для хранения общих префиксов (см. также ), и хранить агрегированные значения в внутренних узлах, что позволяет на этапе вычисления отсекать ветви, основанные на разделяемых измерения. К примеру, дерево подкуба AB может быть использовано для отсечения возможных ячеек в ABD.
Рис. 4.3:
Фрагмент дерева одного из базовых подкубов
Если агрегированое значение, допустим p, не удовлетворяет условию, то бесполезно различать подобные узлы в процессе вычисления куба. Поэтому узел p можно заменить *, еще больше сжимая таким образом дерево. Будем называть узел р узлом-звездой (star-node), если агрегированное значение по измерению в точке p не удовлетворяет условию MinSup. Дерево подкуба, сжатое с помощью узлов-звезд, будем называть деревом звезд (star-tree).
Рассмотрим пример построения дерева-звезд.
 |
Предположим MinSup = 2, тогда только значения

удовлетворяют условию. Все прочие значения превращаются в узлы-звезды. После отбрасывания узлов-звезд получается таблица . Отметим, что эта таблица содержит меньше кортежей и различных значений, нежели исходная таблица фактов. Поэтому для построения подкуба мы будем использовать эту таблицу. Получившееся дерево звезд изображено на рисунке , а таблица узлов-звезд — на таблице . Для выделения узлов-звезд используются таблицы звезд (от англ star-table) для каждого дерева. Пример таблицы подобной таблицы для описанного выше случая приведен на рисунке . Более эффективно использовать битовые массивы или хэш таблицы для таблиц звезд.
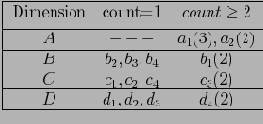 |
 |
 |
 |

на каждом уровне.
Рассмотрим на этом же примере примере, как в работе Star-Cubing алгоритма используются деревья-звезды.
При агрегировании используется дерево-звезд типа того, которое изображено на рисунке . Агрегирование начинается снизу-вверх, при этом используется алгоритм поиска в глубину. Первый этап вычислений (т.е. обработка первой ветви дерева) изображен на рис . В левой части рисунка показано основное дерево звезд. Для каждого значения атрибута изображено агрегированное значение этого узла. Подстрочный номер указывает порядок обхода узлов. Остаются деревья BCD, ACD/A, ABD/AB, ABC/ABC, потомки основного дерева звезд, отвечающие за уровень выше базового на рисунке . Подстрочные номера вновь указывают на порядок обхода.
Например, на первом шаге алгоритма создается корневой узел дерева-потомка BCD, на втором — корневой узел дерева ACD/A, на третьем — корневой узел ABD/AB и узел b*.
Рис. 4.5:
Первый этап агрегирования: обработка левой ветви базового дерева
Рис. 4.6:
Второй этап агрегирования: обработка второй ветви базового дерева
В правой части рисунка показаны деревья в памяти на 5-ом шаге алгоритма. Поскольку к этому моменту поиск в глубину достигает листа дерева, происходит возврат. До возврата алгоритм отмечает, что все возможные узлы базового измерения ABC уже были просмотрены. Это значит, что дерево ABC/ABC уже просмотрено, и результат равен count, а дерево можно удалить. Аналогично, двигаясь назад от d* к c* и принимая во внимание, что у c* нет потомков, алгоритм устанавливает, что count в ABD/AB является финальным результатом, и дерево удаляется.
При возврате в вершине b*, поскольку существует одноуровневый узел

, дерево ACD/A будет сохранено в памяти, и поиск в глубину пойдет от вершины
, так же, как до этого от b*. Результирующие деревья изображены на рисунке . Деревья потомки ACD/A и ABD/A создаются заново, со значениями из поддерева
. К примеру, агрегированное значение с* в ACD/D возрастает от 1 до 3. Деревья остаются неизменными, к ним лишь добавляются новые ветви либо увеличиваются агрегированные значения. Например, дополнительная ветвь добавляется в дерево BCD.
По достижению листа d* алгоритм вновь возвращается, в этот раз до
, где будет замечен одноуровневый узел

. В этом случае будут удалены все деревья, кроме BCD на рисунке . После этого аналогичный обход будет совершен для
. Дерево BCD продолжает расти, а остальные деревья начинаются с корня в
.
Для того, чтобы у узла были потомки, необходимо выполнение двух условий:
узел должен удовлетворять условию MinSup ;
дерево, исходящее из этого узла, должно быть невырожденным, т.е. содержать хотя бы один нетривиальный узел (не узел-звезду).
Это необходимо, поскольку, если все узлы будут тривиальными, ни один из них не будет удовлетворять условию MinSup, и вычислять их будет нецелесообразно.
Подобное отсечение проиллюстрированно на рисунках.
Производительность алгоритма Star- Cubing сильно зависит от порядка измерений, впрочем как и производительность прочих алгоритмов создания кубов типа айсберг. Наилучшая производительность достигается, если измерения обрабатываются в порядке убывания мощности, что повышает шансы отсечений ветвей на ранних этапах вычисления.
Star-Cubing также можно использовать и для полной материализации куба. При вычислении полного куба на плотном массиве данных производительность Star-Cubing сравнима с производительностью MultiWay и намного превосходит производительность BUC. В случае разреженных исходных данных StarCubing намного быстрее MultiWay и в большинстве случаев быстрее BUC. При вычислении кубов типа айсберг Star-Cubing быстрее BUC, если данные распеределены несимметрично, и разрыв в производительности увеличивается по мере уменьшения MinSup.
Вперед: Семантические алгоритмы
Выше: Вычисление Iceberg кубов
Назад: Алгоритм Bottom-Up Computation
Аппроксимирующие алгоритмы
Одновременно с развитием различных методов ''прямого'' сжатия OLAP-данных развивается другое направление оптимизации запросов и хранения кубов — различные методы аппроксимации хранимых данных.
Библиография
1
Гретцер Г. Общая теория решеток. Мир, 1981.
2
Биркгоф Г. Теория решеток. Наука, 1984.
3
Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithms for mining association rules. In Jorge B. Bocca, Matthias Jarke, and Carlo Zaniolo, editors, Proc. 20th Int. Conf. Very Large Data Bases, VLDB, pages 487-499. Morgan Kaufmann, 12-15 1994.
4
Kevin Beyer and Raghu Ramakrishnan. Bottom-up computation of sparse and iceberg cubes. In SIGMOD, 1999.
5
E.F. Codd. Providing OLAP for end-user analysis: An IT mandate. ComputerWorld, 1993.
6
Curtis E. Dyreson, Torben Bach Pedersen, and Christian S. Jensen. Incomplete information in multidimensional databases. In Multidimensional databases: problems and solutions, pages 282-309. IGI Publishing, Hershey, PA, USA, 2003.
7
Sanjay Goil and Alok Choudhary. High performance olap and data mining on parallel computers. Center of Parallel and Distributed Computing Technical Report TR-97-05, 1997.
8
Jim Gray, Adam Bosworth, Andrew Layman, and Hamid Pirahesh. Data cube: A relational aggregation operator generalizing group-by, cross-tab, and sub-totals. Microsoft Lab, 1995.
9
Venky Harinarayan, Anand Rajaraman, and Jeffrey Ulman. Implementing data cubes efficiently. SIGMOD, 1996.
10
H.J. Karloff and M. Mihail. On the complexity of view-selection problem. In PODS, 1999.
11
Laks V.S. Lakshmanan, Jian Peiz, and Yan Zhao. Qctrees: An efficient summary structure for semantic olap. In SIGMOD, 2003.
12
Laks V.S. Lakshmanan, Jian Peiz, and Yan Zhaoy. Socqet: Semantic olap with compressed cube and summarization. In SIGMOD, 2003.
13
Xiaolei Li, Dong Xin Jiawei, and Benjamin W. Wah. Star-cubing: Computing iceberg cubes by top-down and bottom-up integration. In VLDB, 2003.
14
Torben Bach Pedersen, Christian S. Jensen, and Curtis E. Dyreson. Supporting imprecision in multidimensional databases using granularities. In SSDBM, pages 90-101, 1999.
15
Torben Bach Pedersen, Christian S.
Jensen, and Curtis E. Dyreson. The treescape system: Reuse of pre-computed aggregates over irregular olap hierarchies. In VLDB, pages 595-598, 2000.
16
Torben Bach Pedersen, Christian S. Jensen, and Curtis E. Dyreson. A foundation for capturing and querying complex multidimensional data. Inf. Syst., 26(5):383-423, 2001.
17
Nigel Pendse. Olapreport: Database explosion, 2005.
18
Nigel Pendse. Olapreport: What is olap?, 2005.
19
Maurizio Rafanelli, editor. Multidimensional Databases: Problems and Solutions. Idea Group Publishing, 2003.
20
Sunita Sarawagi and Gayatri Sathe. Intelligent rollups in multidimensional olap data. In VLDB, 2001.
21
Yannis Sismanis, Antonios Deligiannakis, Nick Roussopoulos, and Yannis Kotidis. Dwarf: Shrinking the petacube. In VLDB, 2002.
22
Yannis Sismanis and Nick Roussopoulos. The polynomial complexity of fully materialized coalesced cubes. In VLDB, 2004.
23
Erik Thomsen. OLAP Solutions: Building Multidimensional Information Systems Second Edition. Wiley Computer Publishing John Wiley & Sons, Inc., 2002.
24
J. S. Vitter, Wang M., and B.Iyer. Data cube approximation and histograms via wavelets. In CIKM, 1998.
25
Wei Wang, Jianlin Feng, Hongjun Lu, and Jeffrey Xu Yu. Condensed cube: An effective approach to reducing data cube size. In ICDe, 2002.
26
Yan Zhao. Quotient Cube and QC-Tree: Efficient Summarizations for Semantic OLAP. 2003.
27
Yihong Zhao, Prasad M. Deshpande, and Jeffrey F. Naughton. An array-based algorithm for simultaneous multidimensional aggregates. In SIGMOD, pages 159-170, 1997.
Назад: Quotient Cube
Частичная материализация
Частичная материализация предлагает выбор между временем создания кубов и размером хранимых данных, с одной стороны, и временем отклика, с другой. Вместо вычисления полного куба мы можем вычислить лишь некоторые из его подкубов или даже частей подкубов.
Множество работ посвящено выбору набора представлений (подкубов) для материализации, из которых необходимо выделить [9], где впервые была приведена модель оценки стоимости материализации представлений и создания агрегаций. На базе подобных оценок создан алгоритм материализации представлений, оптимизирующий запросы по стоимости. Однако применимость алгоритма [9] и многих последующих алгоритмов сильно ограничена (например типами запросов, распределением данных, структурой куба и пр.). Ограничения накладываются самими авторами, за счет чего часто создаются эффективные алгоритмы. Доказано, что общая проблема выбора представлений для материализации NP-полна [10].
Condensed Cube
В основу этого алгоритма легло наблюдение о возрастающей ''разреженности'' кубов (см. также ). Т.е. с возрастанием числа измерений и иерархий в них, процентное соотношение объема начальных данных к объему всех данных, которые необходимо в общем случае хранить, все возрастает. Рассмотрим граничный пример. Пусть у нас есть отношение R, содержащее только один кортеж
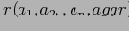
. Тогда результирующий куб будет содержать

кортежей:


Так как в отношении содержится только один кортеж, все

. Следовательно, можно физически хранить только один кортеж

вместе с какой-то служебной информацией, отмечающей, что этот кортеж является ''представителем'' множества кортежей. И для любых запросов по подкубам, нам достаточно возвращать агрегирующее значение изначального кортежа, без каких-либо дальнейших вычислений.
Этот алгоритм обладает рядом следующих отличительных черт.
''Сжатый куб'' (Condensed Cube) не сжимается. Следовательно, несмотря на то, что он обладает меньшим размером по сравнению с полным кубом, это не влияет на выполнение запросов (он не требует разархивирования перед обработкой запросов).
''Сжатый куб'' полностью вычислен. В отличие от многих подходов, предлагающих лишь частичные вычисления подкубов, в данном подходе результатом является полностью вычисленный куб.
''Сжатый куб'' содержит абсолютно точные агрегирующие значения в отличие от различных аппроксимирующих методов.
''Сжатый куб'' удовлетворяет базовым требованиям к OLAP-данным и поддерживает все OLAP приложения в отличие от методов, предлагающих уменьшение размера кубов за счет ограничения возможных запросов.
Ключевым понятием этого алгоритма является ''базовый единичный кортеж'' (Base Single Tuple) — кортеж, который является единственным, формирующим агрегирующие отношения.
Кортежи куба группируются (разбиваются) и агрегируются из базового отношения. В общем случае в любом из разбиений существует большое количество кортежей базового отношения, особенно в подкубах с малым числом измерений. Однако существуют разбиения, содержащие только один кортеж.
Подобные кортежи в дальнейшем называются ''базовыми единичными кортежами''.
Определение 5.1 Пусть

— набор измерений.

. Если

— единственный кортеж в разбиении , образованом по
, то
- базовый единичный кортеж по
, и
— синглетное множество для
. Далее, делается вывод, что если кортеж является базовым единичным кортежем по
, то он является базовым единичным кортежем для любого ''надмножества''
. Кортеж может быть базовым единичным кортежем для нескольких наборов измерений, т.е. для случаев разных группировок ячеек куба возможно существование нескольких срезов, содержащих только одним этот кортеж базовой таблицы. Таким образом, с каждым кортежем связывается множество наборов типа
-

. При этом на всех разбиениях из
агрегирующие значения на любых возможных функциях равны. В дальнейшем, при создании куба эти наблюдения учитываются, и в порожденном кубе все возможные дубликаты базового единичного кортежа удаляются, что приводит к сокращению объема данных и, соответственно, времени выполнения запросов. Для этого вместе с каждой ячейкой хранится служебная информация, указывающая на
этой ячейки и, анализатор запросов учитывает данную информацию при обработке.
Вперед: Quotient Cube
Выше: Семантические алгоритмы
Назад: Семантические алгоритмы
Доказательство
Авторы опускают необходимую при создании DWARF-куба лексикографическую сортировку начальной таблицы (во время создания куба появление нового префикса означает необходимость создания новой вершины на уровне, где различаются префиксы). Сортировка всей фактической таблицы —

или

в лучшем случае (сортировка слиянием, кучами или подсчетом, вычерпыванием). Но с учетом NP-полноты начальной задачи, этим затратами можно пренебречь.
Пусть существует таблица фактических данных с

измерениями (
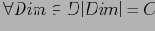
), и количество фактических кортежей

. Не нарушая общности, положим

. У получившегося сжатого куба (или DWARF-куба) корневая ячейка будет иметь вид, показанный на рисунке . Группа

содержит ячейки, не имеющие связи с фактическими кортежами, группа

— ячейки, связанные с одним кортежем фактической таблицы,

— два фактических кортежа.
Вершина G, разбитая на группы, где группа

связана с

фактическими кортежами
Лемма 1
Если из набора равномерно распределенных

элементов выбрать некоторый элемент и повторить выбор

раз, то вероятность выбора этого элемента ровно
раз приблизительно равна:

Равномерность — еще одно ограничение на входные фактические данные. В общем случае:
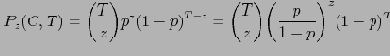
Коротко укажем дальнейшие пункты доказательства.
Применяя лемму 1 к группам
и подставляя

Лемма 2
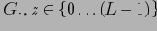
содержит

ячеек, которые адресуют ровно
кортежей.
В общем случае в
попадает

В случае неравномерного распределения кортежей, данная сумма будет отличаться от результатов [22], и это повлечет изменение всех дальнейших оценок в леммах.
Лемма 3
Число дубликатных ключей в вершине, на которую указывает ячейка группы
равно 0. (

)
Основываясь на введенных выше понятиях левого и хвостового сжатий, можно показать, что

и

Здесь

— число ячеек, подвергающихся левому сжатию, и

— число ячеек, подвергающихся хвостовому сжатию.
Из последней формулы получим следующее соотношение для числа ячеек куба:
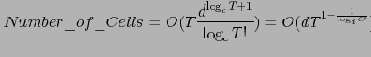
А поскольку при устранении суффиксной избыточности DWARF, в отличие от других алгоритмов, проверяет каждую ячейку только один раз (автору неизвестны алгоритмы, которые для устранения суффиксной избыточности не проверяли бы каждую ячейку экспоненциальное число раз), получаем ту же оценку и для сложности работы алгоритма.
FASMI тест
В дальнейшем Найджел Пендс переформулировал 12 правил Кодда (см. [18]) в более емкий тест FASMI (Fast Shared Multidimensional Information). По определению Пендса, OLAP-система должна быть:
Fast — быстрой, обеспечивать почти мгновенный отклик на большинство запросов;
Shared — многопользовательской; должен существовать механизм контроля доступа к данным, а также возможность одновременной работы многих пользователей;
Multidimensional — многомерной; данные должны представляться в виде многомерных кубов;
Information — данные должны быть полны с точки зрения аналитика, т.е. содержать всю необходимую информацию.
Большинство существующих OLAP-средств удовлетворяет всем этим признакам. Однако в реализации подобных приложений возникает ряд проблем, прежде всего связанных с увеличением объема данных, которые необходимо хранить.
В 1995 группа исследователей во главе с Джимом Греем [8], проанализировав создаваемые тогда пользовательские приложения баз данных, предложила расширение языка SQL — оператор CUBE. Данный оператор отвечает за создание многомерных кубов в SQL. Концепция многомерного представления данных является, наряду с моделью транзакций, одной из самых известных идей Грея. В этой работе исследователи указали ряд эвристических рекомендаций по реализации новой структуры данных.
CUBE представляет собой обобщение операторов выборки с разделом GROUP BY по всем возможным комбинациям измерений с разными уровнями агрегации данных. Каждая сгруппированная таблица относится к группе ячеек, описываемых кортежами из измерений, по которым формируется сгруппированная таблица. Оператор, расширяющий SQL, называется CUBE BY (синтаксис такой же, как и у GROUP BY).
В стандарт SQL'99 включен набор операторов для работы с OLAP-данными (запросы grouping set, rollup by, cube by, window by, rank, rownum и пр).
Вперед: Многомерные кубы, определение и свойства
Выше: Введение. Анализ задачи
Назад: Введение. Анализ задачи
Хранение и эффективный расчет OLAP-кубов
Основными задачами, возникающими при хранении OLAP-данных, считаются хранение разреженных данных и эффективный расчет экспоненциального количества агрегатов, возникающих при добавлении фактических данных (так называемый "взрыв данных", см. [17]).
Iceberg-кубы
Многие ячейки кубов могут не представлять интереса для аналитиков, так как данные в них пренебрежимо малы. Подобная ситуация часто возникает, так как данные разреженно распределены в многомерном пространстве куба. К примеру, клиент покупает каждый раз лишь несколько товаров в одном магазине. Подобное событие будет отражено в виде набора ячеек с малыми показателями мер (объем покупки, количество предметов). В таких случаях полезно предвычислять лишь ячейки со значением меры, большим определенной границы. К примеру, нас будут интересовать лишь покупки на сумму свыше 500 рублей. Такой подход позволяет точнее сфокусировать анализ, не говоря о сокращении времени вычисления и времени отклика. Подобные частично вычисленные кубы называются кубами-айсбергами (англ. iceberg cubes), так как представляют собой вершину айсберга, большая часть которого скрыта под водой. Такие кубы создаются запросами типа Iceberg (см. ).
Простым представляется слежующий подход к вычислению кубов-айсбергов: сначала вычислить весь куб, затем применить условие и отрезать неудовлетворяющие ячейки. Однако это слишком расточительный подход, необходимо вычислять куб-айсберг, не вычисляя полный куб. Подробному анализу методов вычисления таких кубов посвящен раздел .
Однако даже использование ограничений на значение меры может приводить к ситуациям, требующим бессмысленных повторных вычислений. К примеру, в 100-мерном кубе существуют всего 2 ячейки, отличающиеся по значениям одного из измерений. Если меры в этих ячейках больше заданной границы, то будут порождены множество дублирующих эти суммы ячеек (суммы по всем 99 измерениям), при том, что в кубе вообще 3 различных ячейки. Для обработки подобных случаев используется концепция покрытий ячеек, см. .
Вперед: Общие стратегии вычисления кубов
Выше: Введение. Анализ задачи
Назад: Виды запросов к кубам
Иерархии и агрегирование
Иерархичность данных — одно из важнейших свойств многомерных кубов. Иерархии призваны добавлять новые уровни в аналитическое пространство пользователя. Самым распространенным примером иерархии является ''день-неделя-месяц-год''. Соответственно, для уровней иерархии работают отношения обобщения и специализации (rollup/drilldown). Как правило, в научных работах рассматриваются простые примеры иерархий ''детальное значение — ALL'', однако, как мы увидим далее, подобного уровня детализации может быть недостаточно.
Все иерархии можно разбить на 2 типа, о которых пойдет речь ниже. Основой разбиения будет служить расстояние

от корня (

) до листьев. В случае, если
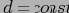
Примеры типов иерархий:
Уровневые:
день-месяц-год; улица — город — страна
Несбалансированные:
Организационная диаграмма, различная группировка продуктов
Важным свойством уровневых иерархий является возможное наличие частичного порядка внутри каждого уровня иерархии, например, возможность сравнения месяцев по старшинству или городов по географическому положению. В большинстве современных средств (алгоритмов) данным свойством пренебрегают , удаляя, тем самым, потенциально полезные связи модели.
Intelligent Roll-Up Queries
Также необходимо отметить, что метод Quotient-кубов дает быстрый ответ на так называемые "умные" roll-up запросы (). Ответ на данные запросы дается во время построения Quotient-кубов, т.к. это и есть верхние и нижние границы кубов.
Вперед: Библиография
Выше: Семантические алгоритмы
Назад: Condensed Cube
Intelligent Roll-Up запросы
Этот термин был введен в работе [20], где был представлен алгоритм создания куба для обработки данного типа запросов. Запрос можно сформулировать следующим образом:
''Каковы наиболее общие условия, при которых значение меры является заданным?''
В отличие от обратных запросов, в данном типе запросов полностью используются все характеристики кубов (иерархичность, многомерность). Легко заметить, что SQL-запросы в таком случае будут иметь сложную структуру, т.к. необходимы именно наиболее общие условия, т.е. максимальные с точки зрения иерархий измерений точки многомерного пространства.
Забегая вперед, отметим, что алгоритм и представление куба с помощью верхних граней обеспечивают быстрый ответ на подобные запросы, т.к. по определению верхняя грань разбиения и есть наиболее общее условие равенства меры определенному значению.
Вперед: Хранение и эффективный расчет OLAP-кубов
Выше: Введение. Анализ задачи
Назад: Многомерные кубы, определение и свойства
Интервальные запросы
Запрос:

Можно превратить такой запрос в серию точечных запросов, но эффективней во время обработки каждого интервала исключать все недостижимые ячейки. Пример:
Порядок обработки запроса (*, книги, еда, весна) следующий:
корень

книги
весна — возвращается значение;
корень
еда — но не можем попасть в ''весну''.
Интервальные запросы (Range queries)
При запросах этого вида возвращается некоторый набор точек куба, удовлетворяющий заданным условиям.
SELECT регион, продукт, SUM(продажи) FROM Продажи
WHERE ((регион = R1) OR ((регион = R2)) AND ((продукт = книги) OR (продукт = еда))
GROUP BY регион, продукт
Результат: продажи книг и еды в R1 и R2
История Задачи
Термин OLAP был введен в 1993 Эдгаром Коддом [5]. Цель систем OLAP — облегчение решения задач анализа данных. Кодд сформулировал 12 признаков OLAP-данных, и большинство современных средств OLAP отвечает этим постулатам. Перечислим их:
Измерения
Измерения куба — набор доменов, по которым создается многомерное пространство. Важной особенностью OLAP-моделей является разделение измерений на локаторы (задающие точки) и меры (задающие значение). Как отмечается в [23], данное разделение может носить как условный, так и жесткий характер. В случае условного разделения измерения можно ''разворачивать'' как данные и как аналитику, создавая новую аналитику куба по продажам — ''количество продаж''. Таким образом, возрастает гибкость моделей и уровень абстракции. Однако данный подход, несмотря на свою привлекательность, сложен в реализации (для примера отметим необходимость создания оптимальных алгоритмов хранения абстрактных типов данных) и, насколько нам известно, нигде промышленно не реализован. Теоретически, вкупе с моделированием решеток кубов логикой предикатов первого порядка, абстрагирование понятия ''измерение'' дает очень интересные результаты.
Локаторы куба отличаются иерархической структурой, и для получения значений мер на каждом уровне агрегирования вводятся агрегирующие функции.
Классификация алгоритмов хранения MOLAP-данных
В дальнейшем, мы будем называть
синтаксическими
— алгоритмы, осуществляющие только синтаксические преобразования данных;
семантическими
— алгоритмы, преобразующие внутреннюю структуру куба;
аппроксимирующими
— алгоритмы, основанные на некоторых средних приближениях значений данных, для которых значение ячейки не всегда совпадает с фактической таблицей.
aлгоритмы вычисления Iceberg-кубов
— выделим данный класс аппроксимирующих алгоритмов
Вперед: OLAP и статистические базы данных
Выше: Введение. Анализ задачи
Назад: Хранение и эффективный расчет OLAP-кубов
Материализация представлений
Главным свойством OLAP-систем считается возможность эффективно отвечать на запросы. Одной из мер повышения эффективности выполнения запросов является материализация кубов, а не вычисление их ''на лету'' (вычисление агрегаций непосредственно во время обработки запроса).
Считается стандартным представление куба в виде так называемой структуры (cube lattice, см. также ) — графа, в котором узлы определяют представления (view) для ответа на запрос. Для каждого узла пометка обозначает измерения, по которым в представлении имеются фактические данные, по значениям ALL производится агрегация. На рис. 1.2 показана структура куба из примера .
Структура куба в виде набора представлений для агрегации
Таким образом, в получившейся структуре куба материализуется набор представлений, содержащий агрегированные данные. Подобные представления также называются подкубами (cuboids). Ячейки базового подкуба называются также базовыми ячейками, ячейки других подкубов называются агрегированными ячейками.
Выбор подкубов для материализации определяет будущую производительность системы. Мы можем получить набор представлений, при использовании которого для выполнения запросов будет не производиться более 1-2 агрегаций (по одному измерению), что означает очень быстрый ответ на запрос. И наоборот, возможна ситуация, в которой для ответа на запрос необходимо будет создавать все агрегации от фактических данных (базового куба). Однако количество подкубов экспоненциально зависит от количества измерения (как
, где n — количество измерений), поэтому для полной материализации может требоваться огромный объем памяти и места на жестком диске.
Многомерные кубы, определение и свойства
Рассмотрим базовую (фактическую) таблицу
, на основе которой мы будем строить OLAP-куб. Множество атрибутов r условно делятся на 2 группы:
Набор измерений (категорий, локаторов), которые служат критериями для анализа и определяют многомерное пространство OLAP-куба. За счет фиксации значений измерений получаются срезы (гиперплоскости) куба. Каждый срез представляет собой запрос к данным, включающий агрегации.
Набор мер — функции, которые каждой точке пространства ставят в соответствие данные.
Из атрибутов
создаются измерения, содержащие проекцию r по атрибуту, с введенной иерархией (например, для таблицы, содержащей фактические данные по продажам магазина, возможно измерение ''Время'', содержащее иерархию вида ''Год-Месяц-Неделя-День''). Куб представляет собой декартово произведение измерений, где для каждого элемента произведения проставлен набор мер (существует проблема хранения неопределенных значений, подробнее см. ). В кубе существуют отношения обобщения и специализации (roll-up/drill-down) по иерархиям измерений (подробнее об иерархиях см. ). Ячейка высокого уровня иерархии может ''спускаться'' (drill-down) к ячейке низкого уровня (для (R1, ALL, весна) может ''спуститься'' к ячейке (R1, книги, весна)) и наоборот, ''подняться'' (roll-up) (от (R1, книги, весна) к (R1, ALL, весна) по измерению ''продукты'').
Многопозиционное агрегирование массивов для вычисления кубов
Многопозиционное агрегирование (MultiWay Array Aggregation, далее MultiWay, см. [27]) рассчитывает полный куб, используя в качестве базовой структуры данных многомерный массив. Это типичный MOLAP-подход, в котором применяется прямая адресация ячеек многомерного массива, и для обращения к элементам измерений используются их индексы или позиции в массиве. Поэтому MultiWay не может использовать ни одну из техник, связанных с переупорядочиванием ячеек в зависимости от значений мер. Укрупненно алгоритм выглядит следующим образом:
Разбиение массива на блоки (chunks). Блоками называются подкубы достаточно малого размера, которые можно разместить в оперативной памяти, выделенной для расчета куба. Разбиение на блоки (chunking) — метод разделения n-мерного массива на меньшие n-мерные блоки, каждый из которых хранится в виде объекта на жестком диске. Блоки сжимаются, чтобы избежать хранения пустых ячеек (см. раздел ). К примеру, ссылки вида (СсылкаНаБлок + СмещениеВнутриБлока) могут быть использованы в качестве механизма адресации ячеек, что позволяет сжимать разреженные массивы и осуществлять быстрый поиск ячеек внутри блока. Подобный подход достаточно эффективен при работе с разреженным кубами как в оперативной памяти, так и на диске.
Вычисление агрегатов при обращении к ячейкам куба. Агрегированные показатели в ячейках вычисляются только в момент обращения к этим ячейкам, поэтому важен порядок обхода ячеек куба. Необходимо минимизировать количество обращений к одной и той же ячейке, поскольку это сократит объем необходимой оперативной памяти и места на жестком диске. Сложность заключается в подборе порядка таким образом, чтобы частичные агрегаты вычислялись одновременно для нескольких подкубов.
Поскольку в таком подходе данные для вычисления агрегатов часто пересекаются, он называется многопозиционным. Агрегирование происходит одновременно по многим измерениям для уменьшение расходов на чтение данных в оперативную память.
Рассмотрим конкретный пример вычисления куба этим методом.
Обратные запросы
Прямой оптимизации по выполнению обратных запросов метод не дает. Но возможно построение индексов B+ деревьев по мерам в QC-деревьях. Это поможет в выполнении обратных запросов, не накладывающих ограничений на измерения. В случае наличия ограничений в запросе можно оставить в QC-дереве только вершины, удовлетворяющие условию и их предков. Получится поддерево, на котором нужно выполнить интервальный запрос.
Обратные запросы (Iceberg queries)
В отличие от точечных и интервальных запросов, для ответа на запрос данного типа используются значения меры (агрегирующие значения). Обратный запрос возвращает все ячейки куба, удовлетворяющие ограничениям, наложенным на значение меры пользователем.
SELECT регион, продукт, время, AVG(продажи)
FROM Продажи CUBE BY регион, продут, время // создается куб
HAVING AVG(продажи) >= 6 // в условии HAVING заключается ограничение на значение меры
Существует множество алгоритмов, ориентированных на обработку исключительно обратных запросов (см например [20,4]). Более подробное обсуждение одного из подобных алгоритмов будет дано далее в разделе .
Общие стратегии вычисления кубов
Вне зависимости от метода хранения (ROLAP, MOLAP), существует набор приемов, позволяющих уменьшить время создания и обработки запросов к OLAP-кубам.
Сортировка, хеширование, группировка
Во время вычисления куба агрегируются кортежи (или ячейки), имеющие одинаковые значения по всем измерениям (так называемые дубликаты), поэтому важно использовать сортировки и группировать данные, чтобы упростить вычисление подобных агрегатов. К примеру, если необходимо посчитать общие продажи по регионам, продуктам, времени года, то более эффективно сортировать кортежи по регионам, затем по по дням и группировать по продуктам. Эффективной реализации подобных операций с большими объемами данных посвящено немало работ в области баз данных. Используемые в этой области алгоритмы могут быть адаптированы для вычислений кубов.
Подобный подход может быть также расширен до разделяемых сортировок (т.е. использованию отсортированных результатов для создания многих подкубов, что позволяет распределить затраты на сортировку) или до разделяемого партиционирования (т.е. разделения затрат на партиционирование при использовании хэширования).
Одновременная агрегирование и кэширование промежуточных результатов
Эффективнее создавать подкубы высоких уровней из подкубов низких уровней, нежели из базовой таблицы. Более того,одновременное вычисление агрегатов может позволить сократить дорогостоящие операции обращения к жестким дискам.
К примеру, для расчета продаж по регионам мы используем промежуточные результаты, полученные при расчете подкуба более низкого уровня продаж по регионам, по дням. Расширение подобного подхода может привести к теории амортизированных чтений (т.е. вычислению максимального количества подкубов за одно обращение к диску).
Агрегирование от наименьшего подкуба-потомка при наличие многих подкубов-потомков
При вычислении подкуба высокого порядка часто более эффективно использовать наименьший из уже рассчитанных подкубов-потокомков.
К примеру, для расчета куба продаж по регионам при условии наличия 2-х рассчитанных подкубов (по регионам и годам, и по регионам и продуктам), очевидно, эффективнее использовать куб по регионам и годам, так как он содержит меньше ячеек.
Использование леммы Apriori при создании кубов типа айсберг
Это правило, используемое при создании кубов типа айсберг, гласит: " Если указаная ячейка не удовлетворяет условию, накладываемому на минимальное значение меры, то ни один из ее потомков не удовлетворяет условию". Этот факт был доказан в [3] и широко применяется в алгоритмах data mining.
При вычислении кубов типа айсберг существенную роль играет выбор условия на меру, которому должны удовлетворять ячейки, чтобы быть включенными в куб. Типичным айсберг-условием является минимальное значение, ячейки с мерой ниже которого исключаются при расчете (например, сумма продаж и количество купленных продуктов). В подобной ситуации условие Apriori может быть использовано для сокращения объема обрабатываемых данных. Например, если количество продаж в ячейке меньше минимально необходимого, то ни в одном из детей этой ячейки количество продаж указанный порог не превысит. Однако нужно отметить, что данное условие верно только для дистрибутивных агрегирующих функций (см. ).
Таким образом, сокращение размера куба — насущная задача создателей OLAP-приложений. Еще одним важным ограничением является требование сохранения семантики отношений обобщения/специализации (roll-up/drill-down). Отбрасывая это требование, многие алгоритмы достигают хороших результатов, но восстановление этих отношений в дальнейшем либо невозможно, либо трудно вычислимо, что существенно ограничивает возможность их применения.
Обзор алгоритмов MOLAP
, факультет ВМиК МГУ
Вперед: Quotient Cube
Выше: Семантические алгоритмы
Назад: Семантические алгоритмы
Обзор алгоритмов MOLAP
, факультет ВМиК МГУ
Вперед: Библиография
Выше: Семантические алгоритмы
Назад: Condensed Cube
OLAP и статистические базы данных
Многие из отличительных черт OLAP-систем, как то:
использование многомерной модели данных
понятия мер и измерений
иерархии в измерениях
понятия roll-up/drill-down
существуют также и в области статистических баз данных, исследования в рамках которой насчитывают не один десяток лет.
Статистическая база данных — БД, спроектированная для поддержки статистических приложений. Из-за различий в терминологии и областях применения признаки сходства между этими типами систем редко обсуждаются. OLAP-системы ориентированы на поддержку больших объемов данных относительно небольшой размерности (максимум 30-40 измерений), а в статистических БД поддерживаются намного меньшие объемы данных большой размерности (300-500 измерений, каждый вопрос исследования определяет измерения, а мерой является просто факт ответа). В статистических базах данных большое внимание уделяется вопросам безопасности данных, например, пользователи статистических исследований могут видеть только суммарные данные и не должны видеть детальные ответы.
Однако в последнее время предпринимаются усилия по объединению исследований в этих областях. Показательной в этом смысле является книга [19], предаставляющая собой тематический сборник статей, посвященных всем аспектам моделирования, хранения и обработки многомерной информации.
Вперед: Требования к многомерным моделям данных
Выше: Введение. Анализ задачи
Назад: Общие стратегии вычисления кубов
Подразделы
История Задачи
12 Признаков OLAP Данных
FASMI тест
Многомерные кубы, определение и свойства
Пример
Измерения
Иерархии и агрегирование
Агрегирующие функции, меры и формулы
Виды запросов к кубам
Точечные запросы (Point queries)
Интервальные запросы.(Range queries)
Обратные запросы. (Iceberg queries)
Intelligent Roll-Up запросы
Хранение и эффективный расчет OLAP-кубов
Представление нулевых данных
Взрыв данных
Материализация представлений
Полная материализация
Частичная материализация
Iceberg кубы
Общие стратегии вычисления кубов
Способы хранения
Классификация алгоритмов хранения MOLAP-данных
OLAP и статистические базы данных
Требования к многомерным моделям данных
Вперед: История Задачи
Назад:
Пример
Измерения
Иерархии и агрегирование
Агрегирующие функции, меры и формулы
Точечные запросы (Point queries)
Интервальные запросы.(Range queries)
Обратные запросы. (Iceberg queries)
Intelligent Roll-Up запросы
Представление нулевых данных
Взрыв данных
Материализация представлений
Полная материализация
Частичная материализация
Iceberg кубы
Способы хранения
Классификация алгоритмов хранения MOLAP-данных
Алгоритм Dwarf
Виды избыточностей структуры куба
Структура куба
Пример куба
Свойства DWARF куба
Выполнение различных типов запросов
Сложность
Виды сжатия
Сжатие Разреженности
Сжатие связанности
Доказательство
Вывод
Многопозиционное агрегирование массивов для вычисления кубов
Пример Вычислений
Вперед: Алгоритм Dwarf
Назад: Требования к многомерным моделям данных
Виды избыточностей структуры куба
Структура куба
Пример куба
Свойства DWARF куба
Выполнение различных типов запросов
Сложность
Виды сжатия
Сжатие Разреженности
Сжатие связанности
Доказательство
Вывод
Полная материализация
Изучение алгоритмов полной материализации помогает в расчетах индивидуальных подкубов, которые в дальнейшем можно хранить на второстепенных носителях, или же создавать полные кубы на основе подмножества измерений и осуществлять детализацию (drill-down) в исходные данные в случае необходимости. Подобные алгоритмы должны быть масштабируемыми, примимать во внимание ограниченное количество оперативной памяти, время вычисления и общий размер расчитанных данных.
Представление неопределенных данных
Одним из важнейших свойств OLAP-систем считается эффективное хранение ''неопределенных данных'' (см. ), поскольку создание многомерных структур порождает появление большого числа точек многомерного пространства, не содержащих значений мер. Например, при формировании куба появляются точки, для которых не было фактических данных, вроде (R2, весна, еда) в примере .
В рассматриваемых ниже алгоритмах, как и во многих других, предлагается следующее решение: не хранить неопределенные значения и, в случае отсутствия данных в кубе, возвращать нулевые значения.
Однако данная проблема схожа с проблемой NULL-значений в базах данных. Возможны следующие случаи отсутствия данных в кубе:
данных быть не может, значение не может существовать;
нулевые данные;
данные еще не получены, необходимо использовать некую формулу для получения значения.
Оставим без рассмотрения случай 3, несмотря на то, что он очень важен для анализа (например, если пользоваться прогнозированием с поквартальным уточнением факта).
В первых двух случаях возникает следующая ситуация — отсутствие данных в кубе означает следующее: либо они нулевые, либо их быть не может. Разница между данными понятиями становится очевидной при необходимости применения функции Average(), т.к. от данного понятия зависит величина Count() (если магазин рапортовал о нулевых продажах товара, он все равно должен попасть в число магазинов, товар продававших).
Данный момент очень важен для построения корректной системы анализа, и, к сожалению, ни в одном из рассмотренных ниже алгоритмов ему не уделено должное внимание.
Схема агрегирования данных для формирования
Рассмотрим пример, который будет и в дальнейшем использоваться в рамках данной работы.
 |
 |
Рис. 1.1:
Схема агрегирования данных для формирования куба
Размер куба данных определяется по формуле
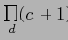
, где
-измерения (''столбцы''), размерность измерения

— количество различных значений кортежей по этому измерению (Select Count(distinct dimension) from table),

отвечает за значение

Таким образом, при базовой таблице в 3 кортежа результирующий куб в простой реляционной таблице (называемой Binary Storage Footprint), в которой напрямую хранятся все агрегаты, занимает 27 кортежей.
Пример куба
|
Для начала приведем пример структуры куба, а в дальнейшем дадим формальное определение. Рисунок показывает структуру куба для таблицы , в качестве агрегирующей функции используется SUM.
DWARF-куб
Вершины пронумерованы в порядке их создания. Высота куба равна числу измерений, каждое из которых относится к одному из уровней, как показано на рисунке.
Корневая вершина содержит ячейки вида {ключ, указатель} для каждого значения первого измерения. Указатель каждой ячейки направлен к лежащей ниже вершине, которая содержит все различные значения следующего измерения, ассоциированные с ключом ячейки.
Каждая вершина содержит специальную ячейку ALL, изображенную серой областью справа от вершины, содержащую указатель и отвечающую всем значениям вершины. Каждый лист L имеет форму {ключ, агрегирующее значение} и содержит агрегирующее значение всех кортежей, которые удовлетворяют пути (паттерну) от корня к L. Каждый лист содержит и ALL ячейку, которая содержит агрегирующее значение всех ячеек вершины.
На рисунке все вершины, к которым идет более одного указателя, поглощают несколько путей (возможных вершин).
Пример Вычислений
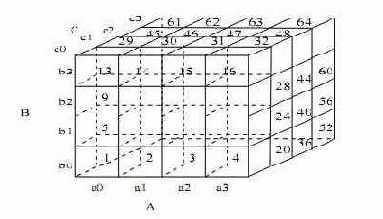
Рассмотрим в качестве примера трехмерный массив данных, состоящий из измерений A, B и С. Он разбит на небольшие блоки, помещающиеся в оперативной памяти. Допустим, всего получилось 64 блока. Измерение А разбито на четыре равномерных участка,
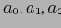
и

. Измерения B и С также разбиты на 4 участка каждое. Блоки 1, 2,..., 64 относятся к подкубам
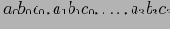
соответственно. Предположим, что размерность измерений A, B и С составляет 40, 400 и 4000 соответственно. Тогда размеры массивов для измерений составляют 40, 400 и 4000 соответственно. Размеры участков, на которые разбиты измерения, составляют 10, 100 и 1000. Полная материализация куба предполагает вычисление всех подкубов, составляющих этот куб. В результате полный куб состоит из следующих подкубов:
Базовый подкуб, обозначаемый ABC, из которого напрямую или косвенно создаются все остальные подкубы. Этот куб уже вычислен.
Двухмерные подкубы AB, AC и BC, отвечающие группировкам AB, AC и BC. Эти кубы необходимо вычислить.
Одномерные подкубы A, B и С, отвечающие группировкам A, B и С. Эти кубы необходимо вычислить
Нольмерный подкуб, обозначаемый all, отвечающий за общий итог по всему кубу, и содержащий только одно значение. Этот куб нужно вычислить. Если, к примеру, мерой куба является count, то значение требуется вычислить подсчетом числа всех кортежей в ABC.
Рассмотрим, каким образом используется MultiWay в таком случае. Существует множество вариантов порядка, в котором подкубы копируются в оперативную память для вычислений. Подкубы пронумерованы в порядке, указанном на рис. . Предположим, мы хотим вычислить блок

подкуба BC. Под этот блок выделяется память в специальном участке памяти, выделенном для создания куба. Для вычисления этого блока требуется использовать блоки с 1-го по 4-ый подкуба ABC. Таким образом, ячейки для
вычисляются агрегированием по A (
). После этого память может быть использована для построения следующего блока

, который вычисляется агрегированием следующих 4 блоков ABC: с 5-го по 8-ой. Продолжая таким образом, мы можем вычислить весь подкуб BC.
Следовательно, в основной памяти достаточно располагать только один блок BC, и эта память используется для вычисления всех блоков подкуба BC.
 |
В процессе вычисления подкуба BC мы были вынуждены прочитать все 64 блока. Однако в большинстве случаев существует возможность избежать повторного чтения этих блоков при вычислении прочих подкубов (таких как AC и AB). Для решения этой задачи и используются многопозиционное агрегирование и одновременное вычисление нескольких кубов. К примеру, при сканировании блока 1 (

) для вычисления двухмерного блока
, могут быть вычислены все остальные двухмерные блоки, относящиеся к
. Во время пребывания
в оперативной памяти вычисляются блоки
,

и

по всем двухмерным подкубам. Таким образом, пока трехмерный блок находится в памяти, MultiWay одновременно агрегирует все соответствующие двухмерные блоки.
Порядок, в котором читаются блоки и вычисляются подкубы, определяет общую эффективность вычислений. Рассмотрим тот же пример с учетом размерностей измерений (40, 400, 4000 для А, В и С соответственно). Тогда наибольшим двухмерным кубом является BC, его размер
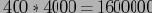
. Следующий по размеру подкуб AC, его размер

. AB — наименьший двухмерный куб размером

Предположим, что блоки читаются в указанном порядке, от 1 к 64. При таком порядке наибольший двухмерный куб BC полностью вычисляется для каждого кортежа. Т.е.
полностью агрегируется на основе участка, содержащего блоки 1-4;
полностью вычисляется на основе участка, содержащего блоки 5-8 и так далее. Для сравнения, полное вычисление одного блока второго по размеру двухмерного подкуба АС в том же порядке 1-64 требует просмотра 13 блоков. К примеру,
агрегируются после просмотра блоков 1, 5, 9 и 13. Наконец, для вычисление последнего двухмерного подкуба АВ потребуется 49 блоков.
полностью вычисляются после просмотра блоков 1, 17, 33 и 49. Таким образом, для вычисления АВ требуется самый длительный просмотр блоков.
Чтобы избежать загрузки трехмерного блока в оперативную память несколько раз, требуется оперативнвя память следующего объема:

Предположим что блоки считываются в порядке 1, 17, 33, 49, 5, 21, 27, 53 и так далее. Тогда сначала вычисляется плоскость AB, затем АС и в конце ВС. Минимальный размер памяти, необходимой для двухмерных блоков, в таком случае составит:
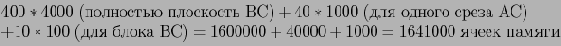
На порядок больше, чем в предыдущем примере.
Аналогично можно вычислить минимальные требования к памяти для вычисления одномерных и нульмерных подкубов. На рисунке изображены наиболее и наименее эффективные пути вычисления. Самое эффективный порядок просмотра: 1-64.
Рис. 2.6:
Различные пути построения подкубов в MultiWay
В приведенном примере предполагается, что имеется достаточно памяти для однопроходного вычисления куба (вычисления всех подкубов за одно чтение всех блоков). Если памяти недостаточно, то может понадобится несколько чтений трехмерного массива. Но и в таких случаях общий подход выбора оптимального порядка чтения блоков остается неизменным. MultiWay наиболее эффективен, когда размерности измерений относительно небольшие и данные не слишком разрежены. Когда размерность измерений очень велика или данные сильно разрежены, массивы становятся слишком большими для загрузки в оперативную память, и метод теряет эффективность.
Экспериментально показано, что при соответствующем выборе техники обработки разреженных массивов и тщательном упорядочивании подкубов MultiWay намного эффективней традиционных ROLAP-вычислений. В отличие от ROLAP, MultiWay не требует дополнительного места для хранения индексов. Более того, в MultiWay используется прямая адресация в массивах, что намного быстрее чтения по ключу в ROLAP-методах. Для ROLAP-вычислений куба было бы эффективней сначала развернуть куб в памяти в многомерный массив, пересчитать и записать результаты в таблицу. Однако подобный подход эффективен при небольшой размерности кубов, ведь количество подкубов растет экспоненциально при добавлении измерений.
MultiWay неэффективен для вычисления кубов типа айсберг, поскольку невозможно использовать . Вычисления в MultiWay идут "снизу-вверх", поэтому нельзя отбросить ни одну из веток вычислений, т.к. сначала просматриваются детальные ячейки, и даже если они не удовлетворяют заданному условию, возможно, этому условию уже удовлетворяют агрегированные ячейки.
Вперед: Аппроксимирующие алгоритмы
Выше: Синтаксические алгоритмы
Назад: Алгоритм Dwarf
QC-Trees
QC-Tree — дерево с разделением префиксов, где грани представляются строчками, а связи отражают необходимые отношения drill-down. Основной идеей QC-деревьев является то, что верхние грани классов куба хранят всю необходимую информацию для выполнения запросов. Т.е. при данном подходе не хранятся даже нижние грани классов. При такой структуре хранения данных запросы над Quotient-кубами выполняются эффективнее запросов над DWARF-кубами. Достигается это превосходство на основе аналогичного по смыслу устранения суффиксной и префиксной избыточностей. QC-деревья позволяют устранять суффиксную избыточность за счет того, что хранятся только классы, а не отдельные ячейки. Префиксная избыточность устраняется за счет свойств самой структуры QC-tree.
Определение 5.5 QC-Tree куба Q — это орграф
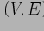
, в котором:

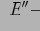
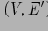
— это дерево;
каждая вершина содержит метку, равную значению одного из измерений;
для каждой верхней грани

существует и единственна вершина

такая, что строчное представление
совпадает с последовательностью меток вершин на пути от корня к

в (V,

); эта вершина хранит агрегирующее значение для
.
предположим, что
и
— классы в

,
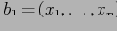
и
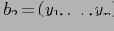
— их верхние грани, и что
(например, что
напрямую специализирует (drills-down)
) в
; тогда для каждого измерения

, на котором различаются
и

, существует либо ребро дерева, либо связь (маркированная

) из вершины
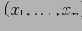
в вершину

.
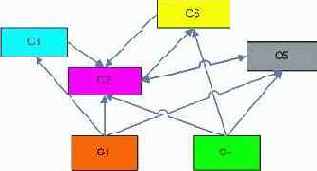
Только последнее из условий требует каких-либо объяснений. Оно просто утверждает, что если С напрямую специализирует D в Q, то это возможно либо по ребру дерева, либо по связи из какого-либо префикса пути, представляющего верхнюю грань С, к вершине, которая приведет к верхней грани D.
| Класс | Верхняя Грань |
| С1 | (ALL,ALL,ALL) |
| С2 | (R1,ALL,ALL) |
| С3 | (ALL,книги,ALL) |
| С4 | (ALL,ALL,осень) |
| С5 | (R1,книги,весна) |
| С6 | (R1,еда,осень) |
| С7 | (R2,книги,осень) |
QC-Tree
Доказана теорема, о том, что QC-дерево для каждого Quotient куба уникально. Существуют алгоритмы создания/поддержки QC-деревьев. Выполнение запросов на QC-деревьях сильно отличается от аналогичных алгоритмов в других методах, т.к. необходимо ''выводить'' содержимое ячейки из верхней и нижней гранях класса. Аналогично, поддержка изменений информации требует пересмотра решетки классов, что, в общем случае, замедляет внесение изменений. В таблице показаны классы и верхние грани Quotient-куба для примерных данных из таблицы , а на рис. — соответствующее QC-Tree.
Разбиение на классы ячеек
Идея этого алгоритма состоит в том, чтобы вместо хранения всех ячеек куба хранить только классы ячеек с одинаковым значением агрегирующей функции. Если же указать выпуклое разбиение (т.е. если две ячейки
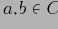
и

), достаточно будет хранить только верхние и нижние грани классов, т.к. все ячейки класса можно будет вывести из этих границ.
Однако разбиение только по значению агрегирующей функции разрушает семантику куба (и тем более не выпукло). Покажем это.
Например, рассмотрим еще раз таблицу Продажи из введения (). Получившиеся разбиение изображено на рис. .
|
Разбиение только по значению агрегирующей функции
У нас получается следующая схема (рисунок ).
 |
Выбор агрегирующей функции в данном случае не важен, т.к. у нас есть возможность двигаться в обе стороны по отношениям roll-up/drill-down. Например, можно пойти вверх от ячейки (ALL, ALL, ALL) в С2 в ячейку (ALL, книги, ALL) в C5, а потом в (R2, книги, ALL) в С2. Тем самым, нарушается семантика отношений roll-up/drill-down.
Таким образом, мы показали, что разбиение только по значению агрегирующей функции не порождает связанной решетки классов эквивалентности. Необходимы какие-то ограничения.
В первых работах по данному алгоритму в качестве разбиения предлагалось так называемое связанное разбиение, однако оно верно только для монотонных функций (Sum (слагаемые одного знака), Count и пр). Впоследствии было предложено разбиение по покрытию. Поэтому здесь в примерах используется AVG — немонотонная функция.
Будем рассматривать кортежи куба как решетку (CL(r), Cube Lattice над отношением r) с введенным порядком, определенным иерархиями измерений (т.е.

). Введем определение покрытия для решетки (см [1],[2])
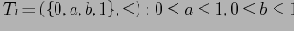
.
Определение 5.2 Будем говорить, что в частично упорядоченном множестве

элемент а покрывает элемент b, или b покрывается элементом a (обозначение:

или

), если:

не существует
, такого, что

Следующая лемма показывает, что отношение покрываемости будет определять частичный порядок на множестве.
Лемма 1 Если
— конечное частично упорядоченное множество, то
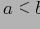
тогда и только тогда, когда
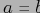
, или когда существует конечная последовательность элементов
такая, что

,

и

для

. Отношение покрываемости в решетке

будет выглядеть следующим образом:
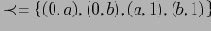
На диаграмме частично упорядоченного множества
элементы изображаются в виде маленьких кружочков

; кружки, соответствующие элементам x и у, соединяются прямой линией тогда и только тогда, когда один из них покрывает другой; если x покрывает y, то кружок, соответствующий элементу x, помещается выше кружка, соответствующего элементу y. Отметим, что в диаграмме пересечение двух линий не обозначает элемент. Диаграмма для решетки
изображена на рисунке .
 |
Кортеж
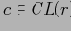
покрывает базовый (фактический) кортеж
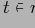
, если
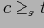
. Определение 5.4 Отношение эквивалентности по покрытию
Определим отношение эквивалентности
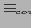
как транзитивное и рефлексивное замыкание

, где:

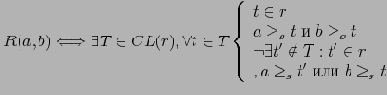
Введенные определения и теоремы позволяют утверждать, что разбиение по покрытию формирует полную решетку куба, только ячейками этой решетки будут являться классы ячеек обычной решетки. Причем у каждого класса будет существовать верхняя и нижняя грань, решетка будет связанной и выпуклой. Значения всех дистрибутивных и алгебраических функций для всех ячеек подобного класса эквивалентности будет совпадать.
Рассмотрим тот же пример, только на этот раз разбиение будет вестись по покрытию (рис. ).
Рис. 5.4:
Разбиение по покрытию
Соответствующая решетка по классам показана на рис. .
Рис. 5.5:
Классы разбиения по покрытию
Таким образом, для получившегося куба нам нужно хранить только две ячейки на класс, верхнюю и нижнюю грань. Остальные ячейки выводятся из верхней и нижней грани, т.к. классы разбиения по покрытиям''полны'' в смысле введенного частичного порядка.
Для Quotient Cube предложено две структуры хранения данных: QC - Tables [12] и QC-Trees [11].
QC-Table — простая таблица, в которой для каждого класса хранится верхняя и нижняя грань. Предложены алгоритмы создания QC-Table и вставки/удаления классов. Такие таблицы неэффективны по времени обработки запросов, т.к. каждый запрос требует просмотра почти всей таблицы.
Сложность
Несмотря на то, что показана NP-полнота общей задачи выбора представлений для материализации [10], в работе [22] были даны новые оценки сложности алгоритма DWARF. Большая часть этих результатов вошла в данный раздел. При этом хотелось бы в очередной раз подчеркнуть, что DWARF — алгоритм полной материализации (materialize-all). Также хотелось бы отметить, что оценки в работе [22] были получены при наложении определенных условий на начальные данные.
С помощью приведенной ниже модели можно показать, что вычислительная сложность алгоритма и объем результирующего куба равны:

— число измерений
— мощность измерения
— число фактических кортежей
Приведем некие трактовки данного результата.
Положим, размерность куба растет , т.е. все кортежи фактической таблицы ''расширяются'' путем добавления новых столбцов. Тогда:

Причем

для реальных баз данных довольно мало.
Правая часть равенства показывает, что размер и время вычисления куба при постоянном числе измерений и добавлении новых фактических кортежей растет почти полиномиально от T, которое возводится в

(что очень близко к единице для больших фактических таблиц).
Модель опирается на понятия префиксной, суффиксной избыточности, приведенные выше в описании алгоритма (см. ). Разобьем категории сжатия на две группы:
сжатие разреженности (sparsity coalescing)
сжатие связанности (implication coalescing)
Способы хранения
ROLAP (Relational OLAP)
— данные, включающие в себя все возможные агрегации, хранятся в реляционных таблицах. Все запросы пользователя транслируются в SQL-операторы выборки из данной таблицы.
Плюсы данного подхода: все данные хранятся внутри одной СУБД в одном формате.
Минусы данного подхода: чрезмерное увеличение объема таблицы данных для куба и сложности пересчета агрегированных значений при изменениях начальных данных.
MOLAP (Multidimensional OLAP)
— все данные хранятся в многомерной базе данных или в специальном формате, определенном создающим и обрабатывающим OLAP-приложением. Все запросы пользователя транслируются в запросы многомерной выборки (MDX, Express 4Gl и др).
Плюсы данного подхода: все данные хранятся в многомерных структурах, что существенно повышает скорость обработки запросов.
Минусы данного подхода: данные куба ''оторваны'' от базовой таблицы, необходимы специальные инструменты для формирования кубов и их пересчета в случае изменения базовых значений.
HOLAP (Hybrid OLAP)
— базовые данные хранятся в реляционной таблице, агрегированные — в многомерной структуре.
Данный метод пытается совмещать достоинства предыдущих, будучи избавленным от их недостатков, но по скорости он проигрывает MOLAP, а также не достигается целостное хранение данных. Возрастают затраты на поддержку и определение типа хранения для подкубов.
Свойства DWARF-куба
Это ациклический ориентированный граф с одной корневой вершиной, имеющий ровно D уровней, где D-число измерений.
Вершины уровня D (листья) содержат ячейки вида {ключ, агрегирующее значение}.
Вершины на уровнях, отличных от уровня D, (нелистовых) содержат ячейки вида {ключ, указатель}. Ячейка С в нелистовой вершине уровня i указывает на вершину уровня i+1, которую она обобщает. С — родительская вершина для обобщаемой вершины.
В каждой вершине имеется специальная ячейка, которая содержит псевдо-значение ALL как ключ. Эта ячейка содержит указатель или на нелистовую вершину, или на агрегирующее значение листовой вершины.
Ячейки на i-ом уровне содержат ключи, являющиеся значениями i-того измерения куба. Внутри одной вершины не может встречаться повторения ключа.
Каждая ячейка

на i-ом уровне структуры отвечает последовательности

из i ключей, входящих в путь от корня до ячейки. Такой путь соответствует оператору group by с (D-i) не указанными измерениями. Все группировки, содержащие
в качестве префикса, будут относиться к ячейкам, являющимся потомками
в структуре куба. Для всех подобных группировок их общий префикс будет хранится единожды.
Когда две или более группировки создают одинаковые вершины и ячейки, их хранение обобщается (поглощается), чтобы можно было хранить только одну копию. В таком случае результирующая вершина будет достижима более чем одним путем из корня, причем все пути будут иметь одинаковый суффикс. Если вершина N — обобщающая, то все ее потомки будут обобщающими вершинами.
Сжатие разреженности
Введем категории сжатия разреженности. Хвостовое сжатие (Tail Coalescing) происходит на всех группировках, имеющих префикс

, где
путь
ведет к подкубу, агрегирующему только один фактический кортеж (см. также ;
путь
не проходит ни через один указатель .
Левое сжатие (Left Coalescing) происходит на всех группировках, имеющих общий префикс

, где
путь
ведет к подкубу, агрегирующему только один фактический кортеж;
путь
проходит хотя бы через один указатель ALL. Области куба, агрегирующие только один фактический кортеж, создают большую избыточность структуры. Ниже будет показано, что избавление от избыточности разреженности приводит к почти полиномиальному времени создания куба.
Примеры категорий сжатия разреженности:
 |
Сжатие связанности
Сжатие разреженности работает только на тех областях куба, где существует только один фактический кортеж. В свою очередь, сжатие связанности расширяет данный метод путем сжатия на подкубах. Например, для таблицы из введения продукт ''еда'' продается только осенью.
Сжатие связанности
Сжатие связанности, таким образом, представляет собой расширение понятия левого сжатия на случай наличия связей (implications) между значениями измерений. Подобные связи часто наблюдаются в реальных базах данных.
Точечные запросы

, где если


.
Алгоритм.

= корень;

=

На любом узле
искать дугу с меткой
,
если существует:

= потомок по найденной дуге;

иначе: проверить последнее измерение j, по которому у
есть потомок.
Если

, тогда

в кубе не появится.
Иначе:
= потомок по измерению j, снова повторяем 2.
Примеры
(R2,*,осень)
начинаем с корня, находим вершину 7, в вершине 7 ищем ''осень'', берем потомка по измерению, продукты, попадаем в 9 — есть ответ.
(R2,*,весна)
все тоже самое, но в 9 мы будем пытаться найти ''весна''
такой ячейки нет
(*,еда,*)
в 5, но там нет значения, ''проваливаемся'' в 6 — ответ
Точечные запросы (Point queries)
При запросах этого вида возвращается агрегирующее значение меры в какой-то ячейке куба, координаты которой задаются в запросе. Все прочие запросы можно переписать, используя серии точечных запросов. Поэтому время выполнения точечных запросов является одной из важнейших характеристик алгоритма хранения OLAP данных.
SELECT регион, продукт, время, SUM(продажи) FROM Продажи
WHERE (регион = R1) AND (продукт = книги) AND (время = весна)
Результат: ячейка (R1, книги, весна)
Требования к многомерным моделям данных
Многомерные модели, предлагаемые алгоритмами, должны, в идеале, удовлетворять перечисленным ниже требованиям, сформулированным в работе [16].
Иерархии в измерениях. Иерархии должны естественным образом описываться и поддерживаться моделью данных. Иерархии определяют поведение roll-up/drill-down.
Многочисленные иерархии в измерениях. В одном измерении может существовать несколько путей агрегирования данных, например, календарный и финансовый год в измерении Время.
Поддержка семантики агрегирования. Модель данных должна позволять задавать различные методы агрегирования, и на основе семантики агрегируемых данных ограничивать "неправильные" запросы, которые могут привести к учету одного факта два раза, суммированию неаддитивных показателей. Например, представляется неразумным суммировать балансовую сумму счета по измерению Время, однако вычисление среднегодового баланса или баланса на последнюю дату представляется логичным. В области статистических баз данных существует понятие "суммируемости" (англ. summarizability), которое означает, что агрегированный результат, например, продажи, может быть получен прямым агрегированием результатов более низкого уровня, например продаж по каждому из магазинов.
Нестрогие иерархии. Иерархии в измерениях могут быть нестрогими, т.е. могут существовать отношения "многие-к-многим" между разными уровнями иерархии. Для примера можно взять почти любую организационную иерархию.
Несбалансированные (non-onto) иерархии. Иерархии в изменениях могут быть несбалансированными, т.е. иметь разной длины пути от вершины к листьям.
Непокрывающие иерархии. Еще одно часто встречающееся на практике условие: узлы иерархии связаны, 'минуя' несколько уровней, например, адрес в пригороде может быть отнесен сразу на уровень "Регион", минуя "Город". Работа [15] посвящена сведению всех подобных иерархий к нормальным, сбалансированным и покрывающим, за счет добавления новых узлов.
Симметричная обработка мер и измерений.
Модель должна позволять использовать измерения, как меры, и, наоборот, меры, как измерения. Например, возраст пациента служит мерой, но для анализа полезно создать разные группы пациентов по возрасту.
Отношения многие-к-многим между фактами и измерениями. Отношение между фактами и измерениями может быть нестрогим. К примеру, у одного пациента может быть несколько диагнозов.
Поддержка изменений и времени. Несмотря на то, что данные меняются с течением времени, должно быть возможно анализировать данные на временном горизонте, включающем эти изменения. Концепция "медленно меняющихся измерений" (Slowly Changing Dimensions, SCD) является частью этой проблемы. Эта же проблема касается "темпоральных баз данных" в более широком смысле. Подобные исследования обычно посвящены подержке временных срезов в контексте реляционных моделей данных.
Обработка разных уровней гранулированности. Фактические данные могут регистрироваться на разных уровнях гранулированности, например продажи в регионе, а не в конкретной кассе. В этих случаях данные должны корректно отображатся и позволять проводить анализ. Очень похоже на непокрывающие/несбалансированные иерархии.
Обработка неточных значений. Необходимо иметь возможность вводить данные с некоторым уровнем точности (часто точное число неизвестно) и на основе этих данных получать корректные результаты запросов. Этой теме посвящены работы [14] и [6].
Вперед: Синтаксические алгоритмы
Выше: Введение. Анализ задачи
Назад: OLAP и статистические базы данных
Вейвлеты
Одной из самых успешных (с точки зрения ожидаемых результатов) работ в области аппроксимации OLAP-данных является [24].
Основными посылками работы явились два наблюдения:
часто встречаются ситуации, когда пользователь предпочтет не точный результат, а некоторый приближенный, особенно если последний можно получить на порядок быстрее;
для ряда приложений возможны ситуации, когда недоступен источник данных, а существует необходимость обработать запрос, даже получив не совсем точный результат.
Рассмотрим особенности работы этого алгоритма. Прежде всего отметим, что это алгоритм нацелен на оптимизацию только одного типа запросов — (range-sum query).
Range-sum query:

Шаги алгоритма:
Шаг Первый
Формируется куб частичных сумм (partial sum cube) — куб, в котором ячейки представляют собой многомерные суммы всех прилежащих ячеек. Это представление данных хорошо тем, что ячейки куба частичных сумм монотонно не убывают по всем измерениям, поэтому аппроксимация подобного куба является более точной, нежели аппроксимация исходного куба. Для ответа на интервальный запрос требуется оценка значения лишь в одной ячейке, а не в целом наборе ячеек.
Partial Sum Cube:

Шаг Второй
Создается новый куб, в котором каждая в каждой ячейке содержится натуральный логарифм значения соответствующей ячейки из куба частичных сумм. Таким образом, еще больше ''сглаживаются'' колебания значений.
Шаг Третий
Формируется декомпозиция получившегося куба, основанная на вейвлетах ( в простейшем случае, хоаровских вейвлетах), — декомпозиция неоднократно применяется для каждого из измерений; таким образом, куб ''складывается'' по каждому из измерений.
Пример декомпозиции сигнала
Положим, у нас есть одномерный набор значений

.
 |
Конечное преобразование сигнала будет выглядеть так

. Подобные преобразования могут выполняться очень быстро. Детальные коэффициенты в данном примере нормализуются по уровню.
В ходе таких преобразований информация не теряется и не приобретается.
Подобная декомпозиция больших объемов данных показывает, что часто коэффициенты, начиная с некоторого значения, отличаются очень слабо. Поэтому мы можем усреднять коэффициенты, считая, что подобные преобразования не сильно повлияют на конечный результат.
Шаг Четвертый
На следующем этапе мы выбираем
главных коэффициентов вейвлетовой декомпозиции данных. Остальные
коэффициентов мы получаем, усредняя начальные
коэффициентов. Хранятся только
коэффициентов куба.
Таким образом, можно сильно сократить объем хранимых данных, почти не теряя в точности результата. Скорость обработки запросов растет в соответствии с уменьшением объема хранимых данных и возможностью обработки запросов путем обращения только к одной ячейке и последующих преобразований данных. При соответствующем выборе коэффициентов скорость этого алгоритма при обработке интервальных запросов превосходит скорость всех других существующих алгоритмов при малом значении ошибки данных.
К сожалению, несмотря на всю эффективность этого метода, он подходит лишь для обработки только одного типа запросов. Более того, для создания кубов этот алгоритм требует достаточного объема вычислений, и результирующий куб почти невозможно изменять при изменениях данных. Применение этого алгоритма ограничено также и тем, что необходимо тщательно выбирать коэффициент
, основываясь на заданном допустимом значении ошибки.
Вперед: Вычисление Iceberg кубов
Выше: Аппроксимирующие алгоритмы
Назад: Аппроксимирующие алгоритмы
Виды избыточностей структуры куба
Определение 2.1 Префиксная избыточность. Пусть имеется есть куб с измерениями a, b и с. Каждое значение измерения a участвует в четырех группировках (a, ab, ac, abc) и, возможно, много раз в каждой из сгруппированных таблиц.
DWARF успешно распознает подобный тип изыбыточности и устраняет его за счет хранения каждого префикса лишь один раз.
Определение 2.2 Суффиксная избыточность
возникает, если 2 или более сгруппированные таблицы разделяют однаковый суффикс (например, abc и bc).
Рассмотрим значение

измерения
, которое появляется в базовой таблице с единственным значением

измерения

. Тогда сгруппированные таблицы
и

всегда будут иметь одинаковые агрегирующие значения. Это происходит благодаря тому, что вторая сгруппированная таблица агрегирует все значения фактической таблицы, которые содержат все возможные комбинации значений измерения (в нашем случае это только значение
) с
и
. Эта идея расширяет понятие базового единичного кортежа (BST, Base Single Tuple) (см. ) из алгоритма ''сжатого'' куба [25]. Поскольку
обычно является множеством значений, суффиксная избыточность может иметь экспоненциальный эффект. Суффиксная избыточность определяется во время создания DWARF-куба и уничтожается за счет поглощения (или слияния) места, занимаемого избыточными суффиксами.
Выполнение различных типов запросов
Точечные запросы
выполняются последовательным разыменованием пути в структуре куба. Таким образом, этот вид запросов выполняется намного быстрее, чем в аналогичных алгоритмах или базовых таблицах, за счет того, что для каждого запроса требуется ровно D обращений к вершинам куба, где D — число измерений (уровней) куба.
Интервальные запросы
включают хотя бы одно измерение с интервалом значений. Для каждого из ключей i-ого уровня, попадающего в интервал, строятся рекурсивные подзапросы к нижележащим подкубам, что тоже достаточно просто по структуре.
Обратные запросы
оптимизаций по выполнению обратных запросов этот алгоритм не дает, но возможно его сочетание с какими-либо другими алгоритмами, ориентированными на обратные запросы. Правда, в настоящее время все оптимизации обратных запросов основаны на специально создаваемых кубах, поэтому такое объединение алгоритмов — нетривиальная задача. См. также .
При использовании этого алгоритма структура
При использовании этого алгоритма структура куба сжимается синтаксически. Префиксная и суффиксная избыточности устраняются за счет создания лучшей системы адресации и хранения ячеек. Алгоритмы, предложенные для создания и модификации кубов с использованием данной структуры, являются наилучшими из всех синтаксических решений на данный момент. Таким образом, если не рассматривать различные эвристические алгоритмы или более глубоких семантические изменения, то в настояющее время этот синтаксический алгоритм или его различные (правда уже частично эвристические) модификации являются оптимальными для хранения и адресации OLAP — данных.
Вперед: Многопозиционное агрегирование массивов для вычисления кубов
Выше: Синтаксические алгоритмы
Назад: Синтаксические алгоритмы
Взрыв данных
При добавлении исходных данных в куб объем данных и время вычисления куба растут экспоненциально, так как необходимо рассчитывать агрегаты по каждому из измерений. Например, десятимерный куб без иерархии внутри измерений с размерностью 100 для каждого измерения приводит к структуре со

ячейками. Даже если мы положим разреженность 1 к

(т.е. пусть только одна из миллиона ячеек содержит данные), куб все равно будет иметь

непустых ячеек. Если пустые значения достаточно легко сжимаются, то "взрывом данных" называют рост количества агрегатов по всем измерениям, которые необходимо вычислить. Т.е. добавление одной ячейки в куб с 10 измерениями, содержащими итоги, приводит к необходимости посчитать

итоговых агрегатов (для устранения подобных cитуаций в каждом из алгоритмов используются специальные техники, к примеру, condensed-ячейки в алгоритме ).